
数据结构
2022 年 5 月 5 日
[数据结构] 顺序表 VS 链表: 详细对比两者优缺点~
顺序表(数组) 和 链表 哪一种结构 更优秀 一点呢?都具有什么 优缺点 呢?
引言
数据结构中有
四大线性表结构: 顺序表(数组) 、链表 、栈 、队列在之前的文章中, 已经详细介绍过
顺序表(数组) 以及 链表 , 思考一下: 顺序表(数组) 和 链表 哪一种结构 更优秀 一点呢?都具有什么 优缺点 呢?这个问题, 其实也是 面试时可能会考的知识点今天, 就来对比一下!
顺序表 和 链表 的优缺点
首先, 先来回答这个问题:
顺序表(数组) 和 链表 哪一种结构 更优秀 一点?答案是: 两种数据结构都很优秀,
没有优劣之分, 只是适用方向不同, 两种结构是相辅相成的分析过 它们 各自的优缺点之后, 就可以非常明显的看出来
顺序表的优缺点
顺序表(数组) 是一种数据在内存中 连续存储 的结构, 即存放数据需要使用连续的物理空间, 这样的结构使它:可以随机访问数据(优点)具体表现为: 数组可以使用下标快速访问数据- 既然需要
使用连续的物理空间, 就涉及到一个非常关键的问题:扩容首先, 扩容本身有一定的时间空间上的消耗, 其次 由于扩容机制(一般二倍二倍的扩容)的原因, 非常可能会造成一定程度上空间的浪费(缺点) - 需要在
顺序表头部或者中间 插入数据 或 删除数据 时, 需要 向后挪动 或 向前挪动 数据, 一般时间复杂度为[O(N)], 存在一定的时间消耗, 效率低(缺点)
具体可以阅读博主文章: ❤️🔥【神秘海域】[动图] 顺序表千字破解~
顺序表存在两个非常不方便的缺点, 所以
链表 诞生了链表的优缺点
谈论链表的优缺点如果谈论
单链表, 那链表的优势就不能完全展露出来, 所以 以带头双向循环链表来对链表优缺点进行分析
与
顺序表 不同的是, 使用 链表 结构在内存中的存储数据, 对内存的使用一般是 不连续的, 因为它的不连续所以:- 在链表中任意位置对数据 插入或者删除 , 都可以 以
[O(N)]的时间复杂度完成, 效率高(优点) - 不需要扩容, 存放数据 即申请即存, 删除数据直接释放,
按需申请和释放(优点) 不能随机访问数据, 只能按顺序从某节点处开始 查找访问 不能随机访问数据,导致链表不适用一些算法: 二分法、随机访问的排序等(缺点)
具体可以阅读博主文章:
❤️🔥【神秘海域】[动图] 掌握 单链表 只需要这篇文章~ 「超详细」
顺序表及链表对比
| 顺序表 | 链表 | |
|---|---|---|
| 空间占用 | 连续的物理空间 | 一般 不连续的物理空间 |
| 访问方式 | 可随机访问😁 | 只能顺序访问🙁 |
| 存储方式 | 顺序存储, 空间不够需要扩容🙁 | 顺序存储, 按需申请和释放 无需扩容😁 |
| 插入删除 | 中间插入需挪动数据, 效率低🙁 | 任意位置插入时间复杂度均为 O(1) 效率高😁 |
| 高速缓存 命中率 | 高😁 | 低(可能存在其他问题) 🙁 |
通过对比可以很明显的看出, 其实
顺序表 和 链表 是互补的存在, 是相辅相成的不过, 这里提到了一个名词
高速缓存命中率下面简单介绍一下, 什么是
高速缓存命中率高速缓存命中率
在 介绍
高速缓存命中率 之前, 先介绍一下 什么是 高速缓存高速缓存
众所周知,
CPU 读取数据是从 内存中读取的, 但是 CPU 读取数据的速度 远远远远大于 内存传输数据的速度所以为了中和 两者之间的差距, 在
CPU 和 内存 之间添加了 数据传输速度介于 CPU 和 内存 之间的 存储器寄存器 和 高速缓存所以目前通用计算机的存储器结构
大致 的示意图如下: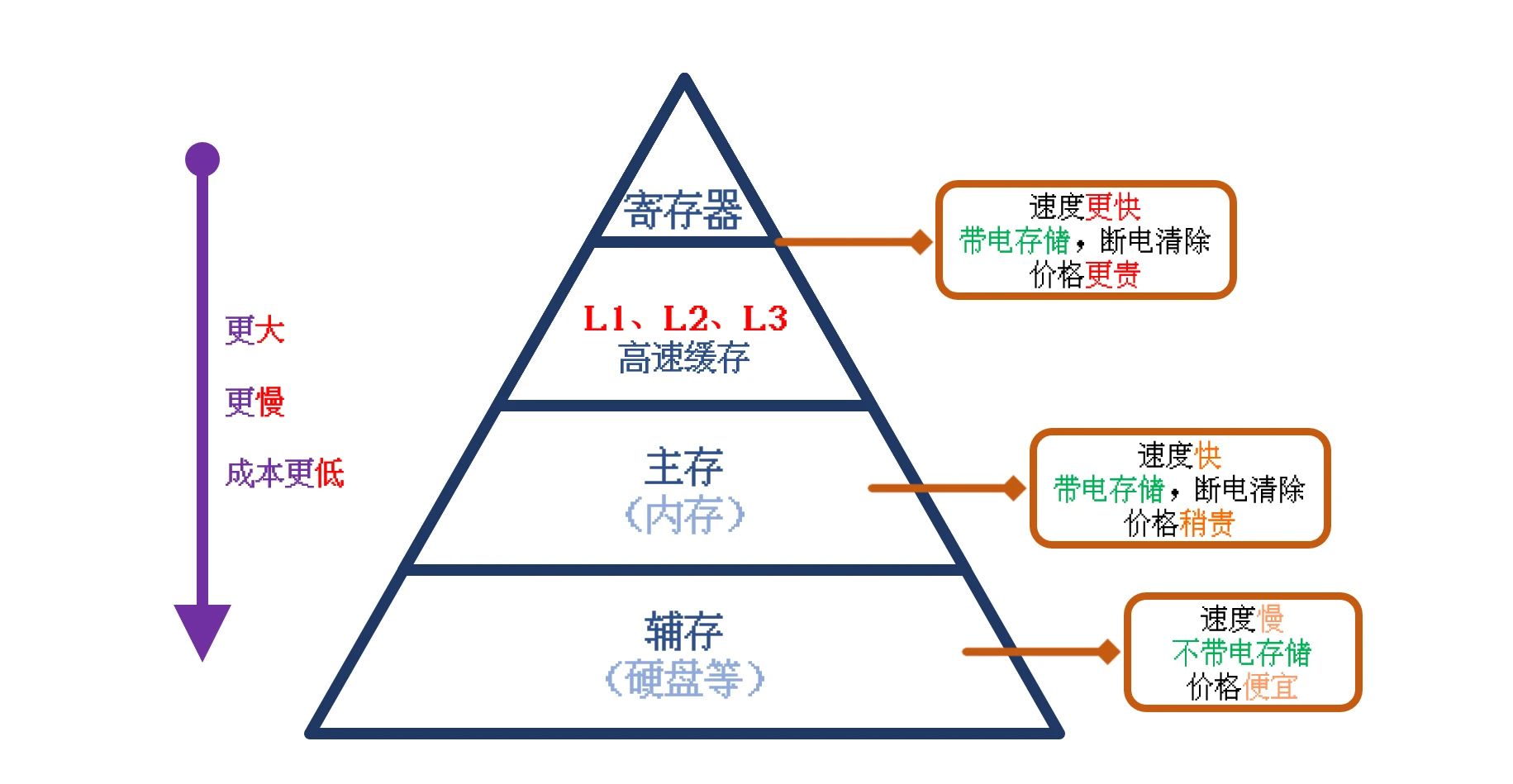
高速缓存 的数据传输速度 一般比 内存 快 5~10 倍, 是为了中和 CPU 读取速度 与 内存 传输速度差距过大而被添加的有了
高速缓存 之后, CPU 读取数据 就会优先从 高速缓存 中读取, 所以, 内存中比较常用的数据 一般 会被存储到 高速缓存 中高速缓存命中率
既然,
CPU 会优先从 高速缓存 中读取数据, 而 高速缓存 中并 不能存储内存中的所有数据 , 那么就一定会存在:CPU从高速缓存中找不到需要的数据, 被称为高速缓存不命中CPU从高速缓存中能找到需要的数据, 被称为高速缓存命中
CPU 从 高速缓存 中 能找到需要数据的次数 与 CPU 从 高速缓存 中 找数据的总次数 的比 就被称为 高速缓存命中率(简称缓存命中率)那么 为什么 用
顺序表 存储数据 缓存命中率 比 用 链表 存储数据 缓存命中率 高呢?顺序表及链表的缓存命中率分析
顺序表 和 链表 的逻辑结构都是线性的但是在实际的内存空间中,
顺序表 是连续存放的, 而 链表 一般并不是连续存放的那么, 使用
顺序表 和 链表 存储数据, 在内存中大致的的存储情况应该是这样的:顺序表: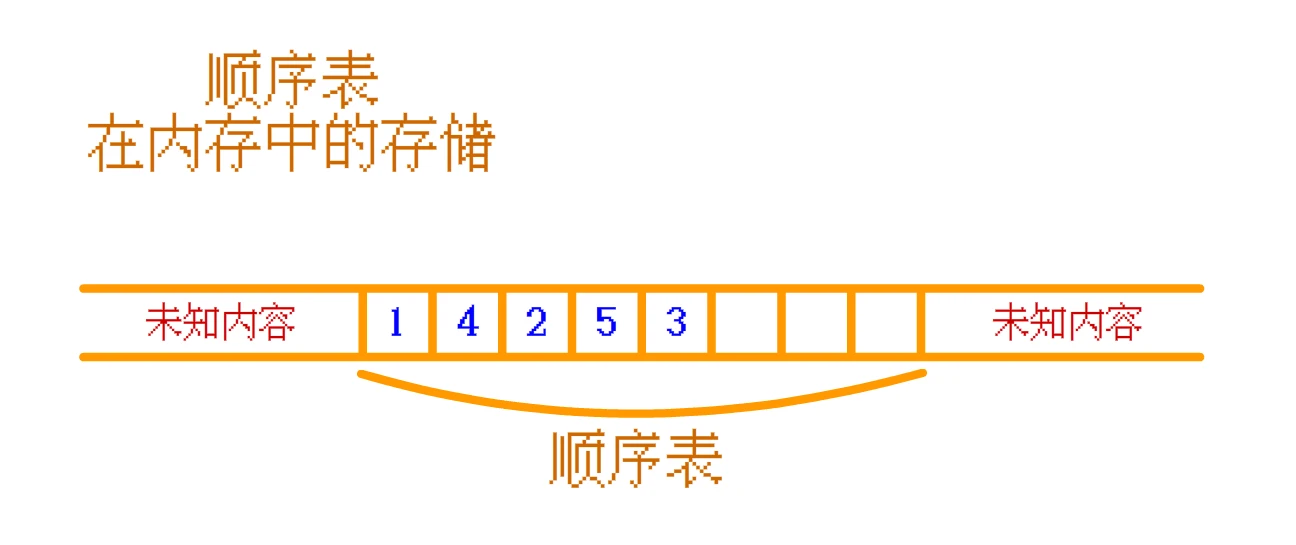
链表: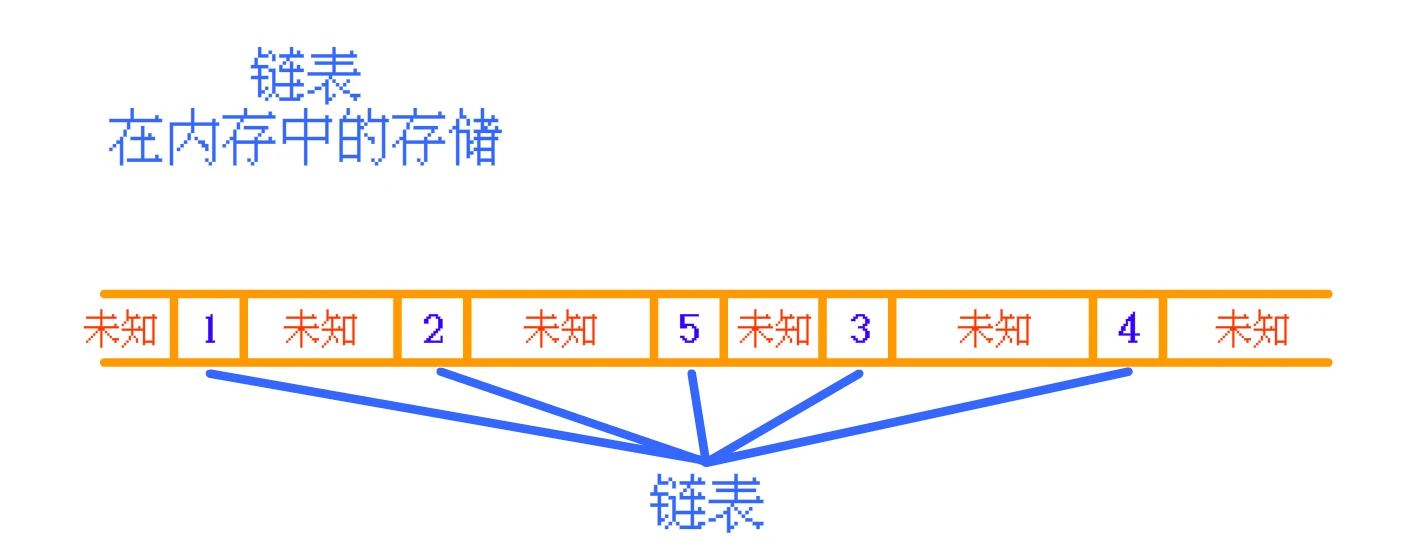
假设, 这两个结构的数据都
没有被存入高速缓存 中, 当 CPU 需要读取数据的时候
CPU读取数据, 如果没有在高速缓存中读取到, 就会去内存中寻找, 然后再将寻找到的数据及其周围的数据存入高速缓存中以提高缓存命中率
对于
顺序表 :如果需要读取
顺序表中的 4 , 高速缓存中没有, 那么 CPU 就会再往 内存中 找, 找到之后会将 顺序表中的 4 及其周围的一部分数据 一起存入 高速缓存 中。如果 CPU 需要再次访问 顺序表 中其他的数据时, CPU 大概率可以直接从 高速缓存 中找到相应的数据。如此,
顺序表 的 高速缓存命中率 就 高。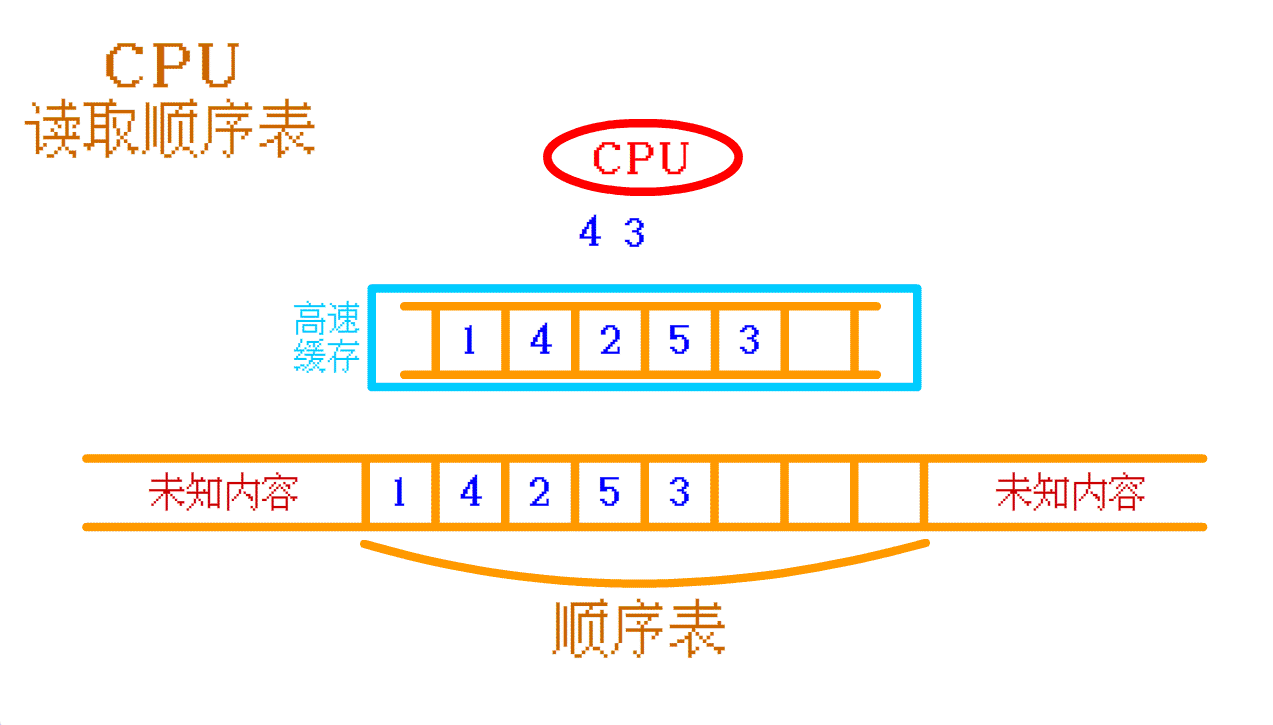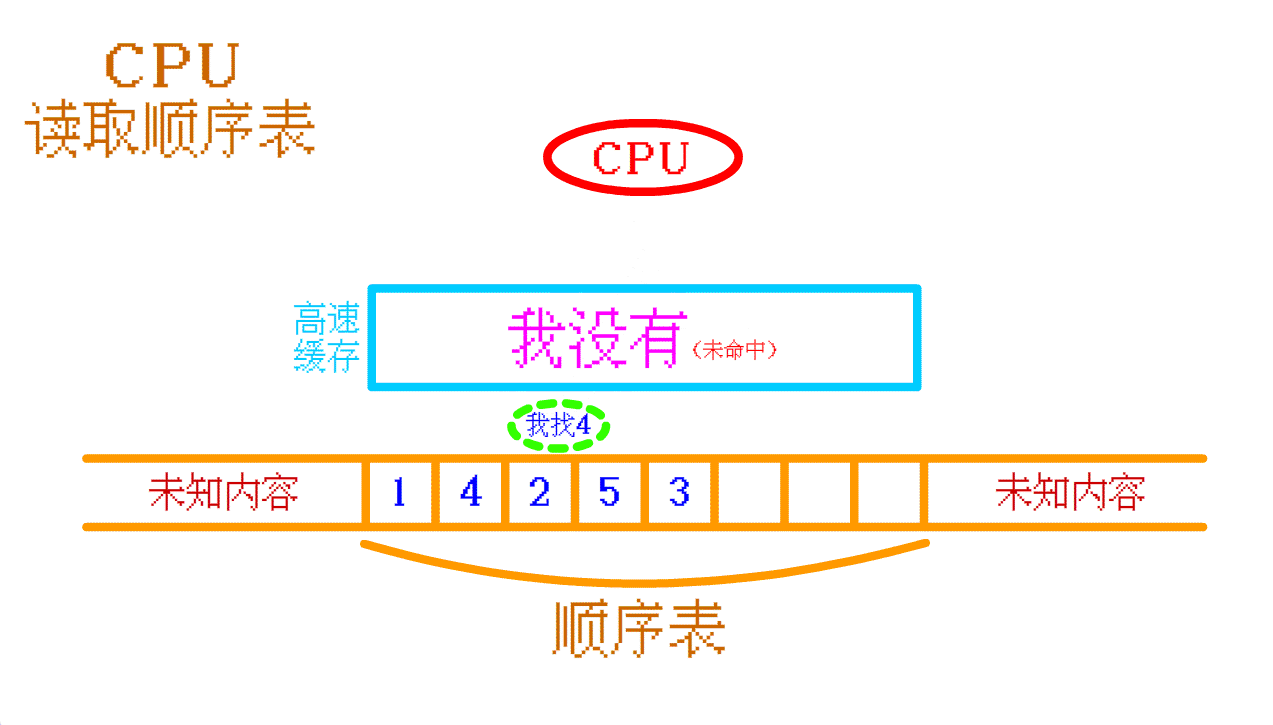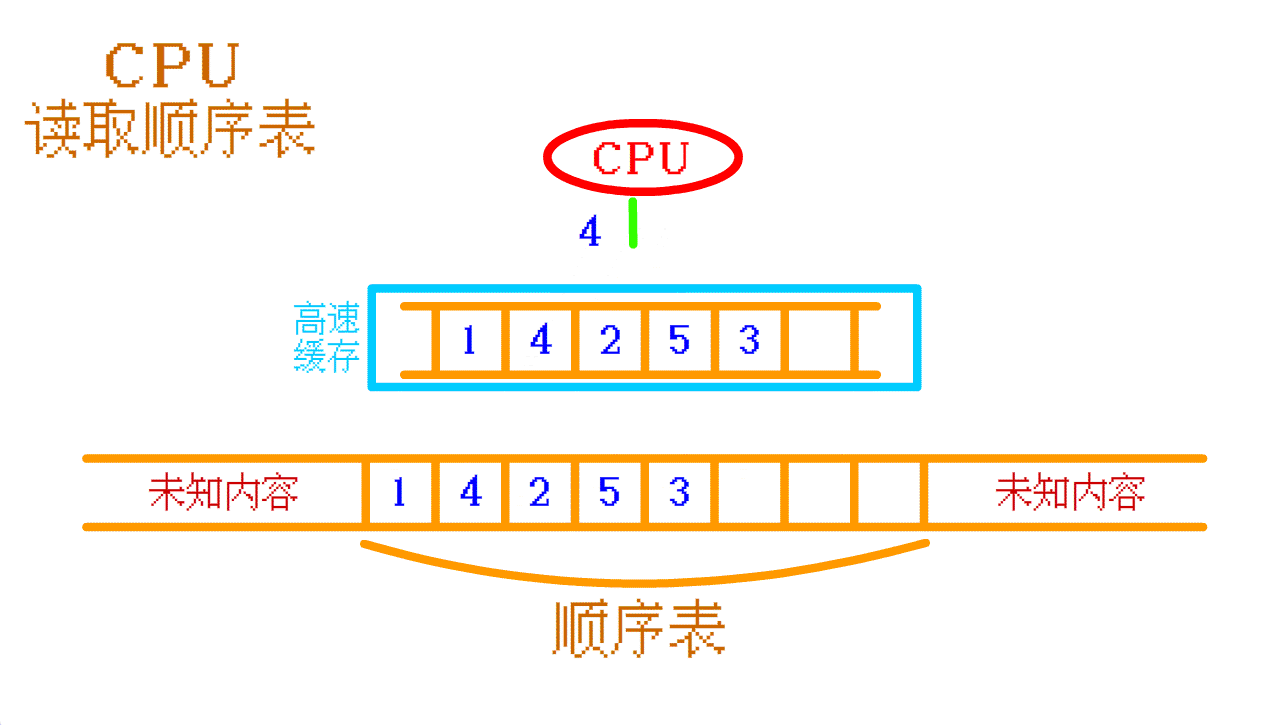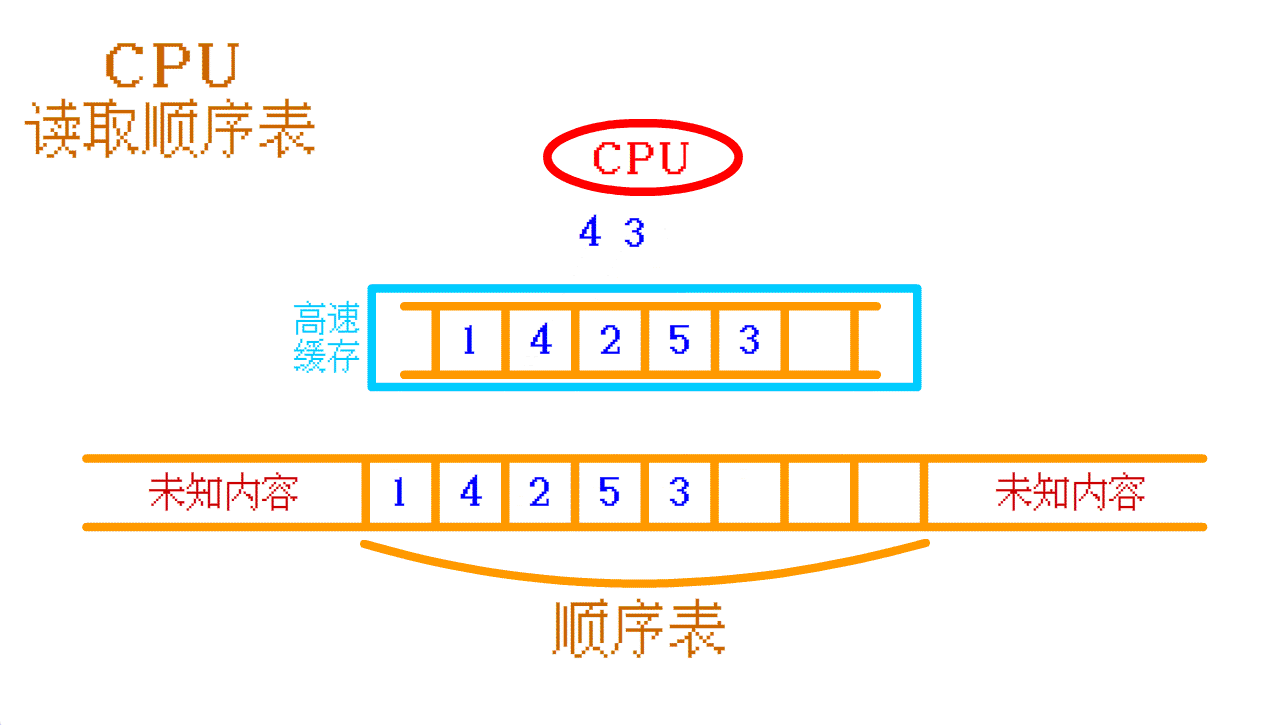
cache_Seq
对于
链表:如果需要读取
链表中的 2 , 高速缓存中没有, CPU 同样会去 内存中 找, 然后再将 找到的数据及其周围的数据 存入高速缓存。但是, 由于 链表中 的数据在内存中一般并 不是按顺序存放 的, 所以如果 CPU 需要再次访问 链表 中的其他数据时, 很可能不能直接从 高速缓存中 找到。没有找到, 就又需要向 内存中 寻找。所以
链表 的 高速缓存命中率 就 低。
cache_list1
结语
本篇文章是
顺序表 与 链表 的结尾, 将 顺序表 与 链表 进行了对比, 希望可以让你对 这两种结构有更深刻的理解。线性的数据结构, 四已介绍其二。希望对你有所帮助~
OK, 本篇文章就到这里~
版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
作者: 哈米d1ch 发表日期:2022 年 5 月 5 日