
Linux网络
2024 年 1 月 20 日
[TCP/IP] 传输层代表协议--TCP协议介绍(4): 滑动窗口、快重传机制、流量控制、拥塞控制、粘包等概念 简单介绍分析...
TCP协议是面向连接的, 面向字节流的, 可靠的 传输层协议...
滑动窗口**
为了保障数据传输的可靠性,
TCP协议实现了确认应答机制以及超时重传机制为实现确认应答机制,
TCP协议包头中包含了序号和确认序号为实现超时重传机制,
TCP协议同时拥有发送缓冲区与接收缓冲区, 但只是拥有发送缓冲区, 明显不能实现超时重传的机制使用
TCP协议传输数据时, 发送方是可以发送一批数据的, 只要接收方完整收到了这一批数据, 就需要应答对应的确认序号当发送方长时间没有接收到应答, 就需要重新将数据发送出去, 以此保证数据传输可靠
要实现超时重传, 就意味着数据发送之后不能丢弃, 需要存储一定的时间, 直到确认对方完整的收到
那么, 已经发送出去 但是还没有确认被接收的数据存储在什么地方呢?
实际还是在
TCP的发送缓冲区中存储, 这与TCP的发送缓冲区逻辑结构有关TCP发送缓冲区可以看作是一块连续的空间, 但在逻辑结构上内容大致可以分为三部分: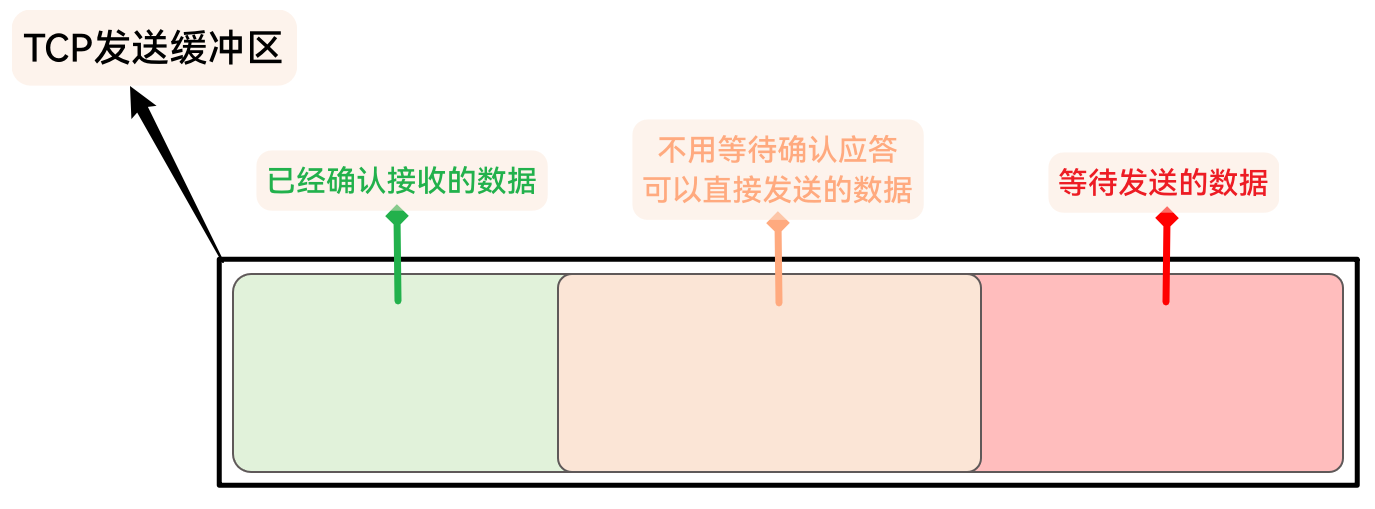
-
已经确认接收的数据
即, 已经发送, 并且已经收到了确认序号的数据
例子:
如果, A发送了[1000, 1100]序号的数据, B全部收到了并响应了确认序号1101, A也收到了确认序号1101
那么A [1000, 1100]的数据, 就属于已经确认接收的数据
-
不用等待确认, 可以直接发送的数据
这一部分稍微有一些不好理解
这一部分数据, 可以看作 已经发送但还未收到确认序号 + 下次需要发送的部分数据(还未发送, 准备发送)
例子:
A发送了[1000, 1100]序号的数据, 但是B只完整收到了[1000, 1066]序号的数据, 所以B响应确认序号1067
A收到了1067的确认序号, [1000, 1066]就会属于 已经确认接收的数据, [1067, 1100]就会属于 不用等待确认, 可以直接发送的数据
并且, 根据B接收能力的大小, 这一部分可能还会增加一些新的需要发送的数据
这一部分也可以理解为, 下次准备发送的数据
-
等待发送的数据
之后再发送的数据
例子:
如果, A发送了[1000, 1100]序号的数据, 并且还未收到确认应答, 那么[1101, …]的数据就是等待发送的数据
中间 不用等待确认应答, 可以直接发送的数据 部分, 即为 滑动窗口, 也被称为发送窗口, 这一部分实际表示 准备发送的数据
从发送缓冲区的逻辑结构来看, 其实 发送出去的数据并不会从发送缓冲区中删除掉, 而是根据情况考虑是否会再处理
而滑动窗口中的数据, 就是接下来需要发送的数据. 这一部分数据, 可能是上一次发送过 但未被确认应答数据, 也可能是从未发送过 但已经准备好发送的新数据
滑动窗口的大小, 是根据对方接收窗口的大小动态维护的, 并且 当发送方收到确认序号之后, 滑动窗口的左边界就会移动到序号为确认序号的数据处, 再视情况维护右边界
从滑动窗口的维护逻辑上看, 就像是在发送缓冲区中维护了一块向右滑动的大小不固定的空间, 这也是滑动窗口名字的由来
在发送缓冲区中, 被滑动窗口滑过的数据是可以被删除掉的, 当滑动窗口右边界 到 发送缓冲区右边界已满时, 就会从发送缓冲区的头开始放入新数据
当然, 滑动窗口要控制在发送缓冲区的内部, 而发送缓冲区是存在边界的, 所以, 当滑动窗口滑动到发送缓冲区的右边界之后, 滑动窗口就要从发送缓冲区的左边界重新开始维护
快重传**
上面已经了解了, 需要重传的数据会被维护在滑动窗口中
不过, 除所有数据都没有收到 然后超时之外, 什么时候才会可能需要重传数据呢?
有两种情况需要考虑一下:
- 接收方收到了数据, 但是 确认应答丢失 了
- 接收方没有收到其中的一部分数据, 即 一部分数据丢失 了
第一种情况:
如果接收方发送的确认应答丢失了, 并不需要特殊处理
因为, 接收方已经收到数据了, 如果后面收到数据, 会应答更大的确认序号, 此时如果发送方接收到更大的确认序号, 就能够确认之前的数据也已经收到
而第二种情况:
如果发送方发送了
[1001, 1100], [1101, 1200], [1201, 1300], [1301, 1400]接收方 没有收到
[1101, 1200] 的部分, 其他部分数据都收到了但如果接收方窗口大小允许, 此时发送方可能依旧在发送数据, 还在发
[1501, 1600], [1601, 1700], [1701, 1800]…接收方 没有收到
[1101, 1200] 的部分, 但是发现 发送方还在发送新数据, 所以 接收方可能会快速多次响应确认序号为1101的应答当 发送方接收到3个及以上相同的确认应答之后, 就会直接重传对应的数据, 不需要等到超时
接收方收到丢失的数据之后, 会直接响应到已经收到的所有数据的序号
这样的重传机制, 被称为 快重传
流量控制
滑动窗口中的数据, 表示下次准备直接发送的数据
滑动窗口的大小, 会根据接收方的接收缓冲区剩余空间的大小进行调整
而接收方接收缓冲区的大小, 会在
TCP报头中的窗口大小中对应的填充, 发送方就可以 根据对方报头中的窗口大小来调整滑动窗口的大小, 进而控制发送方的流量接收方的窗口大小, 关系着本次连接实时的网络吞吐量
接收方窗口大小越大, 当前网络吞吐量就越高, 反之则越小
接收方一旦发现接收缓冲区的容量快没有了, 就会将窗口大小填充一个更小的值, 发送方就会减小滑动窗口的大小, 进而减慢发送数据的速度
当接收方的接收缓冲区满了, 就会将窗口大小填充为0, 发送方也会将自己的发送窗口大小维护为0, 进而停止发送
但, 如果此时双方都不再发送数据, 就会出现一个问题: 数据通信就此停止
所以, 发送方即使停止了数据的发送, 也依旧 会定期发送一个窗口探测数据段, 让接收方应答一下自己的窗口大小, 以恢复后续通信
拥塞控制**
TCP协议为了保证通信双方之间可以可靠、高效的通信, 为通信双方做了许多的机制: 确认应答、延迟应答、超时重传、快重传、滑动窗口、流量控制…但是, 网络通信要关注的并不只有通信双方, 因为无论是什么协议, 数据都是要发送到网络中的
TCP协议为通信双端做了那么多事情, 如果在通信时还是发生了大量的丢包, 那么可能就是网络出了问题, 毕竟网络中并不是只有这一条连接的使用
TCP通信, 当此次发送的数据报大量的丢失, 大量的传输失败, 此时TCP协议就会认为是网络出了问题网络可能当前压力过大, 已经堆积了大量的数据包进行处理, 此时 即使出现了大量的丢包,
TCP协议也不能直接进行重传因为, 如果网络出了问题, 那就不是两台主机的事, 而是所在网络区域所有主机的事情
如果, 此时网络发生拥塞, 所有主机的使用
TCP协议都发生了大量丢包, 还要一起进行超时重传, 只会加重网络的拥塞情况, 可能会引起更严重的丢包情况所以, 当
TCP判断网络发生拥塞时, 不会执行超时重传的机制, 而是 会进行拥塞控制TCP协议除了滑动窗口和接收窗口之外, 还维护有另外一个窗口: 拥塞窗口, 此窗口不在协议报头中维护实际上, 滑动窗口的大小, 是根据 当前拥塞窗口大小 和 对方接收窗口大小 一起决定的, 以较小值作为参考调整滑动窗口大小
当网络发生拥塞时,
TCP协议会将拥塞窗口的大小设置为1, 滑动窗口的大小也会随之控制到1个数据包在此之后,
TCP每次接收到ACK响应时, 拥塞窗口的大小就会变为二倍, 即:在网络发生拥塞之后 拥塞窗口的大小 会从1开始指数增长, 直到拥塞窗口的大小达到一个设定好的阈值. 当拥塞窗口的大小 达到此阈值之后, 会变成线性增长, 直到滑动窗口的大小不再以拥塞窗口大小为参考进行调整(即 网络恢复畅通)
指数级增长是一个很恐怖的增长速度, 为什么拥塞窗口要指数级增长呢?
思考一个问题,
TCP通信时 网络发生拥塞, TCP最想要做的是什么?一定是: 尽快恢复正常通信, 但又不能加重网络拥塞
但是, 网络问题不是主机端能够解决的, 所以主机端只能等待, 等待网络恢复正常
不过又不能什么都不做干等, 所以
TCP需要不停的尝试向网络中发送数据, 试探网络的状态但是 又不能 一下发送大量的数据, 否则可能会加重网络的拥塞状态
所以,
TCP要先向网络中发送少量数据, 如果能够收到响应, 即表示 以现在的数据量, 是可以保证通信可靠的那么, 下次发送数据就尝试扩大一倍的数据量, 如果还是能够收到响应, 就重复扩大数据量
这样可以达成两个目标:
- 刚开始不会发送大量数据到网络中, 也就大概率不会加重网络拥塞
- 如果网络拥塞恢复, 指数增长的速度, 可以保证
TCP通信快速恢复正常状态
因为, 滑动窗口的大小是根据
min(拥塞窗口大小, 对端窗口大小)所以在网络拥塞时, 一般只需要扩大拥塞窗口就能够实现拥塞控制
而在网络状态恢复之后, 即使拥塞窗口过大, 也不会影响滑动窗口大小, 因为此时一般会按照对端窗口大小维护滑动窗口
不过, 拥塞窗口也不会无限制的指数级扩大, 而是达到一个阈值之后, 转换为线性增长, 对滑动窗口无影响时, 或许就不再增长了
而, 如果拥塞窗口还未停止增长, 却又发生了网络拥塞, 此时,
TCP会重新开始进行拥塞控制, 但线性阈值一般会变为本次发生网络拥塞时, 拥塞窗口大小的一半这就是
TCP的拥塞控制, TCP拥塞窗口的增长方式被称为TCP慢启动, 因为启动时速度比较慢, 但增长速度比较快TCP粘包问题**
什么是粘包
TCP协议是面向字节流的, 面向字节流就表示在数据传输时, 应用层发送的数据在传输层默认不会存在数据边界, 会以流的形式传输, 像水流一样没有分割即, 如果应用层发送
1 + 1和2 + 2, TCP协议不会在乎什么1 + 1和2 + 2, TCP很可能因为要发送的数据内容太小 而将1 + 1和2 + 2按顺序 无间隔 的放在TCP的发送缓冲区中, 等待时机将数据一起发送走而, 接收端的
TCP协议接收到数据时, 一定也不会在乎有效载荷的内容是什么, 只会将有效载荷原封不动的放在接收缓冲区中此时, 如果 应用层需要读取数据, 大概率会读取到像
1 + 12 + 2这样 原则上是两条数据 但却没有界限的一条数据这种情况, 就是
TCP的粘包现象上述场景是
TCP粘包现象出现的一种可能TCP粘包问题, 并不只是发送端可能造成的问题TCP协议是存在接收缓冲区的, 并且, 接收缓冲区是流式的, 即 连续的空间TCP通信时, 发送端发送的数据, 接收端接收到数据之后, 会将数据按顺序 无间隔 的放在接收缓冲区中, 等待应用层的读取也就是说, 即使
TCP发送端确实将1 + 1和2 + 2分开发送了, 但是接收端 也可能将两次收到的数据1 + 1和2 + 2按顺序 无间隔 的放在接收缓冲区中, 即 1 + 12 + 2那么此时, 应用层读取数据时, 依旧会读取到
1 + 12 + 2这样粘在一起的两条数据粘包问题 会严重影响应用层处理数据, 所以, 无论是应用层还是
TCP协议都需要尽可能的对粘包问题做一些处理如何避免 或 减少粘包
已经了解了什么是粘包, 也了解了为什么会出现粘包的现象
那么, 避免或减少粘包的出现 就有了一定的方向:
-
在对端窗口允许的情况下, 发送端将应用层发送的每条数据都单独发送走
这样可以从发送方, 减少粘包发生的可能
-
在接收端, 应用层要及时处理 传输层接收缓冲区的数据, 尽量 避免数据在接收缓冲区堆积
这样可以从接收方, 减少粘包发生的可能
-
应用层在发送数据和接收数据时, 规定好数据格式, 即 将数据在应用层就规定好边界
前两个方向, 很容易理解, 即尽量不让数据在
TCP发送缓冲区或接收缓冲区堆积, 这样应用层读取数据更小的几率读取到粘在一起的数据而第3个方向, 就是在应用层的方面的
粘包问题 影响的是, 应用层对传输层的数据的处理, 由于数据与数据之间没有明显的界限, 导致应用层无法正确的处理数据
而 应用层要处理的数据, 实际也是来自对端的应用层
那么, 要避免粘包问题的出现, 最容易也最简单的方法就是 应用层在发送数据时, 就对发送的数据做好界限分割
这样也可以看作是从数据的源头解决了粘包问题
只要在应用层做好了数据与数据之间的界限分割,
TCP协议再怎么堆积数据, 对端应用层永远可以将数据与数据之间有效的分离开, 进而能够有效的处理数据UDP为什么没有粘包问题?
版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
作者: 哈米d1ch 发表日期:2024 年 1 月 20 日