
[TCP/IP] 网络层代表协议--IP协议介绍(1): IP协议 数据格式、... 简单介绍
-
应用层:
HTTP和HTTPS -
传输层:
TCP和UDP
ipv4做介绍IP协议
TCP/IP协议栈中:-
应用层:
主要做数据的处理工作, 包括: 序列化/反序列化, 协议处理, 分析读取完整报文等
-
传输层:
TCP协议需要实现的最重要的工作是 保证数据在网络中传输的可靠性
A向B发信息, A向网络中发送数据, B就是A发送数据的目的地IP协议就可以让主机拥有, 在网络中寻找主机的能力IP协议, 主机B就能将数据通过网络”传送”到主机C中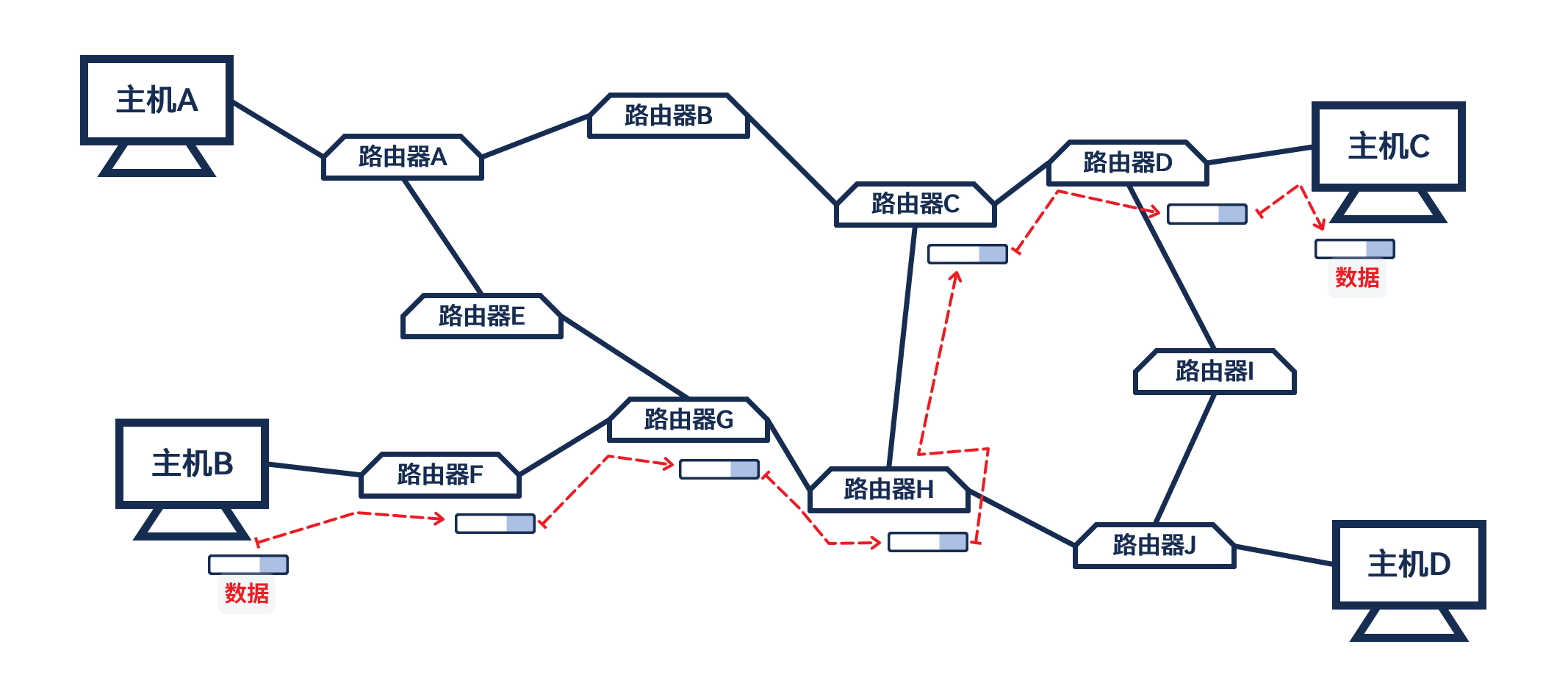
主机: 拥有
IP地址, 但不做路由控制的设备(有能力, 但不做)路由器: 拥有
IP地址, 并做路由控制的设备节点: 网络中主机和路由器的统称
IP并不提供传输可靠性的保障, 数据在网络中传输的可靠性是TCP协议实现的. 如果 IP数据包丢失, 同样也包含了TCP数据包的丢失, TCP协议就可以对数据传输可靠性实现保障TCP协议与IP协议IP协议IP协议格式
TCP协议相同, IP协议 以ipv4报头的标准长度为20字节:
ipv4协议报头的字段:-
[0, 3]: 4位版本, 用以区分IP协议的版本, 现在熟知的就是ipv4和ipv6, 此字段就是用来区分协议版本的不得不说, 协议的设计者是真的有前瞻性, 早早的就将区分版本的字段给留了出来
-
[4, 7]: 4位首部长度, 用于记录当前报头大小, 4位可表示0~15, 计算报头大小时 要*4, 所以报头大小范围为:20~60字节 -
[8, 15]: 8位服务类型(TOS)其中, 前三位[8, 10]为优先权字段, 但已经弃用
[11, 14]为TOS字段, 只允许最多有一位设置为1, 分别表示: 最小延时, 最大吞吐量, 最高可靠性, 最小成本 (即, 需要实现什么属性)
[15]保留字段, 没有使用
此字段一般不需要进行设置, 除非真的有需求
-
[16, 31]: 16位总长度(字节), 用于记录当前报文大小 -
[32, 47]: 16位标识, 起 报文分片标识作用 (后面介绍) -
[48, 50]: 3位标志, 起 报文分片标志作用, 第一位保留不用 (后面介绍) -
[51, 63]: 13位片偏移, 起 报文分片整理作用 (后面介绍) -
[64, 71]: 8位生存时间(TTL), 标识IP报文在网络中的最长生存时间当数据被发送到网络中之后, 数据会经过许多次的路由转发
正常情况下, 经过许多次的路由转发, 数据可以正常的被对端主机接收到
但是在不正常的情况下, 可能因为一些情况对端无法接收数据, 数据可能在网络中不断路由, 即 数据在网络中游离. 此时, 就需要将数据丢弃掉, 防止占用网络资源
此字段, 即 表示数据可在网络中路由转发的最长次数, 即 数据在网络中转发的跳数
不可过大, 不可过小
-
[72, 79]: 8位协议, 用于表示上层(传输层)使用协议, 用于分用 -
[80, 95]: 16位首部校验和, 用于校验协议报头是否损坏 -
[96, 127]: 32位源IP地址, 记录发送方主机IP地址, 很重要的字段 -
[128, 159]: 32位目的IP地址, 记录目的主机的IP地址, 很重要的字段 -
至此, 一共
[0, 159]位, 20字节, 即ipv4首部标准长度为20字节 -
可能: [160, ...]: 选项, 一般情况下不会使用, 具体选项 具体分析
TCP/IP协议栈, 同主机不同层级之间传输数据, 存在三个操作: 封装、解包、分用关于这三个操作的概念:
封装:
TCP/IP协议中, 当上层需要将数据发送到下层时, 就要对数据进行封装封装, 即 在有效数据之前添加所用协议的报头
然后, 才会将封装好的数据交付给下一层
解包:
在
TCP/IP协议中, 当对端主机接收到完整数据时, 会对数据进行解包解包, 即 对接收到的数据, 将数据中 同协议的报头部分解析并去除掉
比如, 如果传输层使用
TCP协议发送数据, 那么接收方的传输层接收到数据之后, 会分析数据的TCP报头, 并将有效载荷(不包括协议报头的数据部分)提取出来然后, 才会将有效载荷交付给上层
分用:
在
TCP/IP协议中, 当对端主机需要将数据从下层交付到上层时, 需要进行分用分用, 即 将有效载荷交付给上层中指定的协议, 因为相同协议才能正确处理数据中的协议报头
因为, 同一层中会存在很多不同的、使用场景不同的协议, 所以需要解析出需要数据封装时所使用的协议, 才能将数据交付给上层
IP协议报头中:[4, 7]位字段: 4位首部长度, 可以有效解决封装与解包的问题, 这个字段表示协议报头大小, 所以可以将数据中 协议报头有效解析出来, 进而可以解包[72, 79]位字段: 8位协议, 可以有效解决分用的问题, 这个字段存储的内容是上层所使用的协议, 所以在向上层交付数据时, 读取此字段就可以解决分用问题IP协议的分片

IP协议可能会对传输层交付下来的数据进行的一种分割操作. 如果传输层交付过来的数据较大, IP协议会对传输层交付过来的数据进行分割, 并 会分别对分割出来的数据进行封装. 这个行为被称为分片IP协议如果收到的上层数据过大, 就会对数据进行分片- 对端主机如何确认数据是否分片?
- 如何确认分片数据之前是否属于同一数据?
- 如何确认已经完整的收到了同一数据的所有分片?
- 如何对已经分片的数据进行还原?
-
对端主机 如何确认数据是否分片?
当
IP协议需要对数据进行分片时, 会对分片数据的IP协议报头的[48, 50]: 3位标志的对应位, 进行填充第
[48]位, 保留位 不被使用第
[49]位, 如果此位被设置为1, 表示禁止IP协议对数据分片. 此时, 当数据过大时, 将会被直接丢弃第
[50]位, 用以表示 是否有更多分片:当 此位被填充为1, 表示后面还有更多分片, 同时也表示 当前数据为分片数据
当 此位被填充为0, 表示后面没有更多分片 或 表示此数据为非分片数据
是否有更多分片是什么意思呢?
当,
IP协议对数据进行分片时, 会按照分先后顺序对数据进行分片如果,
IP协议接收到6230字节的上层数据, 就会对数据进行分片, 可能会将[0, 1023][1024, 2047][2048, 3071][3071, 4085][4096, 5119][5120, 6143][6144, 6229]字节的数据, 均进行封装, 分片为个7最大不超过1500字节的IP数据报那么对于前6个分片数据,
IP协议报头的第[50]位, 会被填充为1, 最后一个分片数据的 则会被填充为0所以, 当读取到
IP协议报头的第[50]位为1时, 就说明还有属于同一数据的分片报文 -
对端主机 如何确认分片数据 之前是否属于同一数据?
[32, 47] 16位标识, 就是用来标识 分片数据原来所属的数据的如果,
IP协议需要对接收到的数据进行分片, 就会将这些分片的16位标识 均填充为相同的值这样, 对端主机读取时, 就能够识别到分片数据 所属的原数据
-
对端主机 如何确认已经完整的收到了同一数据的所有分片?
首先, 对端必须接收到 报头第
[50]位为0的分片数据然后就要根据
[51, 63] 13位片偏移确认是否有分片数据丢失了[51, 63] 13位片偏移, 填充的是 分片之后数据的首位置 相对 于原数据首位置的偏移量 再/8根据偏移量是否连续, 就可以确认是否完整的收到了同一数据的分片
因为, [51, 63]为填充的是分片偏移量/8
所以, 除了最后一个分片, 前面分片的大小需要为8的倍数
-
对端主机 如何对分片数据进行还原?
根据
[51, 63] 13为片偏移进行还原
[32, 47]: 16位标识 [48, 50]: 3位标志 [51, 63]: 13位片偏移三个字段的作用, 均与分片有关IP协议并不能保证数据可靠性, 当对端主机 没有收到任意一个分片数据, 就会将其他所有 所属同一数据分片全部丢弃IP协议对数据进行分片子网划分**
IP地址
IP地址, 在网络中是用来确定主机的IP地址, 这样能够在网络中确认唯一的主机, 然后才能通过IP地址实现不同主机之间的通信 (是IP唯一, 不是主机只拥有唯一的IP)ipv4协议的IP地址为4字节, 日常通过点分十进制的方式表示, 比如: 192.168.5.111. 点分十进制表示IP地址, 每个点将分隔8位数据192.168.5.111实际表示的是 11000000 10101000 00000101 01101111, 刚好四个字节IP地址的这四个字节, 由两部分组成: 网络号 + 主机号. 网络号用于标识两个不同的网段, 主机号用于标识同一网段中的不同主机192.168.5.111, 如果前24位都由网络号占用, 那么最后8位就由主机号占用, 那么192.168.5的这个网络中, 最多可以有0~255台主机IP地址来快速地相互找到的呢?IP地址的IP地址, 由两部分组成: 网络号 和 主机号IP地址, 所以路由器也能够接收数据, 并且路由器会根据数据的IP报头中的 目的IP地址的网络号进行转发为什么路由器 通过网络号找目标网络 可以更快速地找到目标主机?
因为, 找目标网络可以按照网络排除一批主机, 而不是一个一个主机对比
IP划分方式
IP由两部分组成, 网络号和主机号ipv4的IP地址也就32位, 最多有256*256*256*256(4,294,967,296)个IP地址, 并且是全球共用的IP地址, IP的网络号和主机号是有划分方式的IP地址分为了5类:
-
A类, 前8位为网络号, 且必须最高位必须为0包含
IP地址为:0.0.0.0到127.255.255.255后24位为主机号, 那么
A类网络中, 可包含主机数:256*256*256(16,777,216), 用于大型网络 -
B类, 前16位为网络号, 且最高两位必须为10包含
IP地址为:128.0.0.0到191.255.255.255后16位为主机号, 那么
B类网络中, 可包含主机数:256*256(65536), 用于中型网络 -
C类, 前24位为网络号, 且最高三位必须为110包含
IP地址为:192.0.0.0到223.255.255.255后16位为主机号, 那么
B类网络中, 可包含主机数:256, 用于小型网络 -
D类, 不做日常使用, 用于组播通信, 最高四位必须为1110包含
IP地址为:224.0.0.0到239.255.255.255 -
E类, 一般不用, 最高五位必须为11110包含
IP地址为:240.0.0.0到247.255.255.255
IP被浪费, 因为一申请A类或B类, 就至少是65536个IPIP的. 被申请过的网络号又不能给其他人用, 所以就会造成很多IP浪费CIDR(Classless Interdomain Routing) 无类别域间路由:-
引入一个叫 子网掩码(subnet mask) 的东西, 用于划分 网络号和主机号;
-
子网掩码是一个32位正整数, 子网掩码 由高位开始置1, 如果高位有N个1, 就表示对应
IP高N位为网络号比如
若存在
IP以二进制表示:11000000 10101000 00000101 10011101(192.168.5.157)若其高位前24位为网络号, 那么对应的子网掩码就应该是:
11111111 11111111 11111111 00000000, 高24位置1 -
如果直到
IP地址 和 子网掩码, 要求获取IP地址的网络号, 就可以IP地址 & 子网掩码 计算子网掩码还有一种方式表示,
IP/子网掩码位数
IP, 与A、B、C类IP无关子网掩码划分的优点
-
使用子网掩码, 可以更细化地划分
IP地址比如 最小可以划分出 只有两台主机的网段, 只需要将子网掩码设置为
11111111 11111111 11111111 11111110, 即 前31位是网络位那么, 一个网段中 最多只有两台主机
-
使用子网掩码, 可以更灵活地划分子网
IP地址如果是类别划分, 就只有那三种类别可以在日常中使用, 网络号就只有8位、16位和24位三种情况
而使用子网掩码划分, 可以随意地在合法范围内划分网络号的位数, 从1位到31位都可以
IPv4地址的限制
IPv4协议的IP地址是32位的, 最多也就40多亿的IP地址IP并不会被设备联网使用:0.0.0.0, 代表当前主机所在的整个网络127.*, 用于本机IP地址环回, 通常为127.0.0.1255.255.255.255, 即IP地址的32位全设置为1, 表示广播地址, 当向此IP发送数据时, 表示向同一子网中的所有主机发数据
CIDR大大减少了IPv4地址的浪费, IP地址好像也完全不够用-
动态分配
IP地址即, 在设备不接入网络时 不分配
IP地址, 在接入网络时, 动态分配IP地址所以, 同一个网卡设备, 每次接入网络时,
IP可能并不会相同 -
使用
IPv6协议IPv6协议的IP地址是128位的,IPv6地址的数量级是 10的38次方, 而IPv4只有10的9次方IPv6号称可以给地球上的每一粒沙子都分配一个IP地址所以, 使用
IPv6好像可以没有后顾之忧的解决IPv4地址不足的情况不过,
IPv6还没有完全发展起来, 并且与IPv4完全不兼容
但是, 为什么现在绝大多数还是使用的
IPv4呢? -
NAT技术*NAT技术, 是IPv4依旧坚挺的最大原因之一, 篇幅原因暂不介绍
公有IP和私有IP**
IP地址可以用来表示网络中主机的地址, 但 并不是所有IP都能出现在公网上IP, 是连接在全球互联网上的IP, 在全球范围内是唯一的IP, 则表示内部网络的IP, 不直接在全球公有互联网中进行路由, 即 私有IP不会出现在公网之中IP地址是可以重复的IP的地址可以是任意的, 但RFC 1918规定了用于组建局域网的私有IP地址, 只能为一下这些:10.*, 至少前8位为网络位172.16到172.31, 至少前12位为网络位192.168.*, 至少前16是网络号
IP. 在公网中, 是看不到这三个范围的IP的IP地址, 就可以确定此IP是私有IP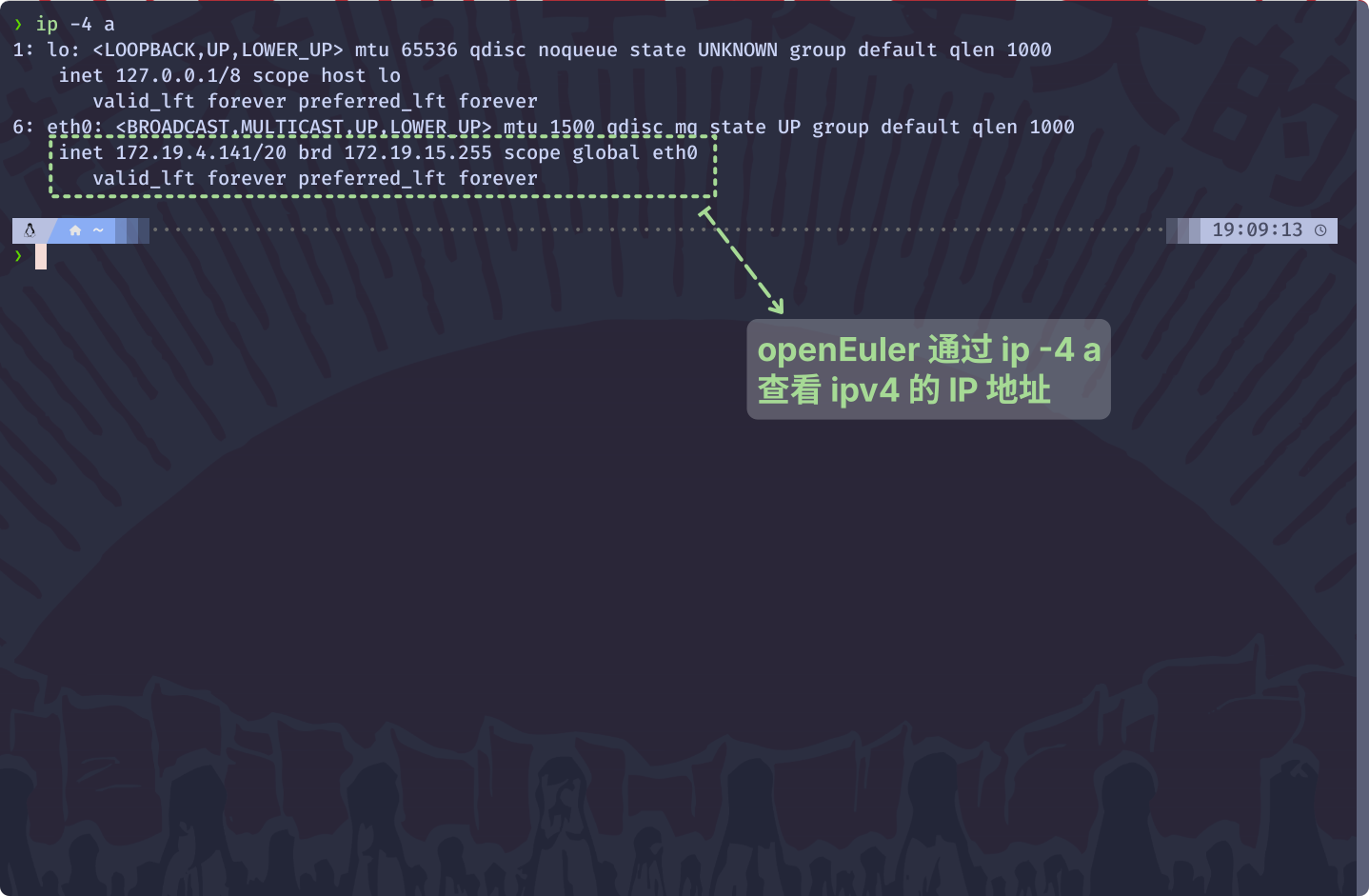
172.19.4.141/20就是本机的私有IP, 前20位是网络号, 后12位是主机号IP在不同的网络中可以重复, 即 这里一个网络中可以有 192.168.5.111, 另一个网络中也可以有 192.168.5.111, 只要能让私有IP也能够与全球的互联网通信, 就能够很大程度上解决IP不足的问题NAT(Network Address Translation)就是 使用 公有IP结合私有IP 解决IPv4协议的IP不足的问题的NAT技术
NAT(Network Address Translation) 网络地址转换作者: 哈米d1ch 发表日期:2024 年 9 月 4 日