
[Linux] 详析进程控制: fork子进程运行规则?怎么回收子进程?什么是进程替换?进程替换怎么操作?
再识fork()
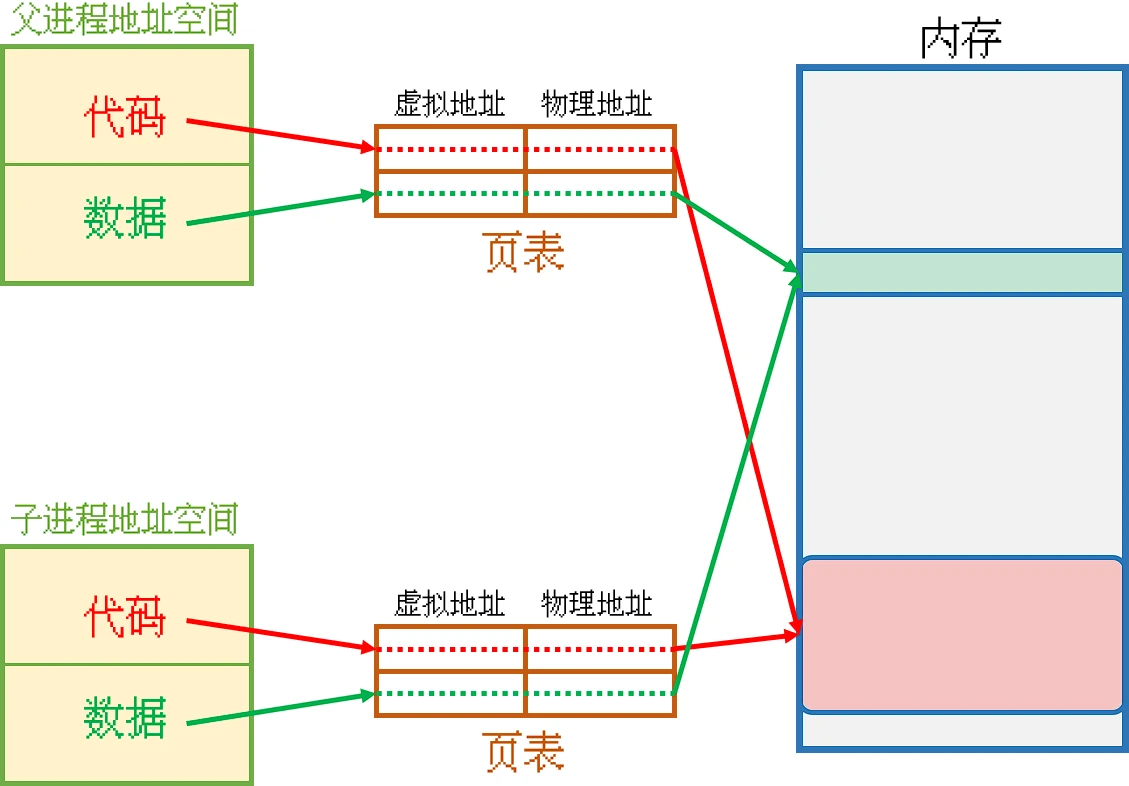
fork()创建出子进程之后, 一般情况下父子进程的虚拟地址其实指向的是同一块内存物理地址. 这样就实现了父子进程共享代码和数据, 并且在父子进程写入数据的时候, 操作系统采用的是写时拷贝的做法既然父子进程共用同一块代码, 按理来说子进程应该从头开始运行, 那为什么子进程只运行fork()之后的代码?为什么子进程只运行fork()之后代码
程序计数器, 有时也叫PC指针, 此寄存器中存储的内容是: 当前指令的下一条指令的地址.写时拷贝
当进程需要写入数据的时候, 操作系统才会将需要写入的数据另外拷贝一份供进程写入写时拷贝当然只针对数据, 而不针对代码. 因为正常情况下程序运行起来之后, 代码不可更改 属于只读的数据.
为什么需要用写时拷贝的做法?为什么要用写时拷贝?
为什么要写时拷贝?直接拷贝不可以吗?在子进程被创建出来的时候, 为什么不直接将父进程所有的代码和数据都另外拷贝一份放入内存中供子进程使用?-
在子进程被创建出来的时候, 就将父进程的所有代码和数据拷贝一份, 当然可行.
但是, 如果父子进程所执行的代码从头到尾都没有对数据进行修改的操作, 或者只修改了非常小的一部分数据, 那为什么要全部拷贝一份呢?
在这种情况下是否存在空间浪费的嫌疑? -
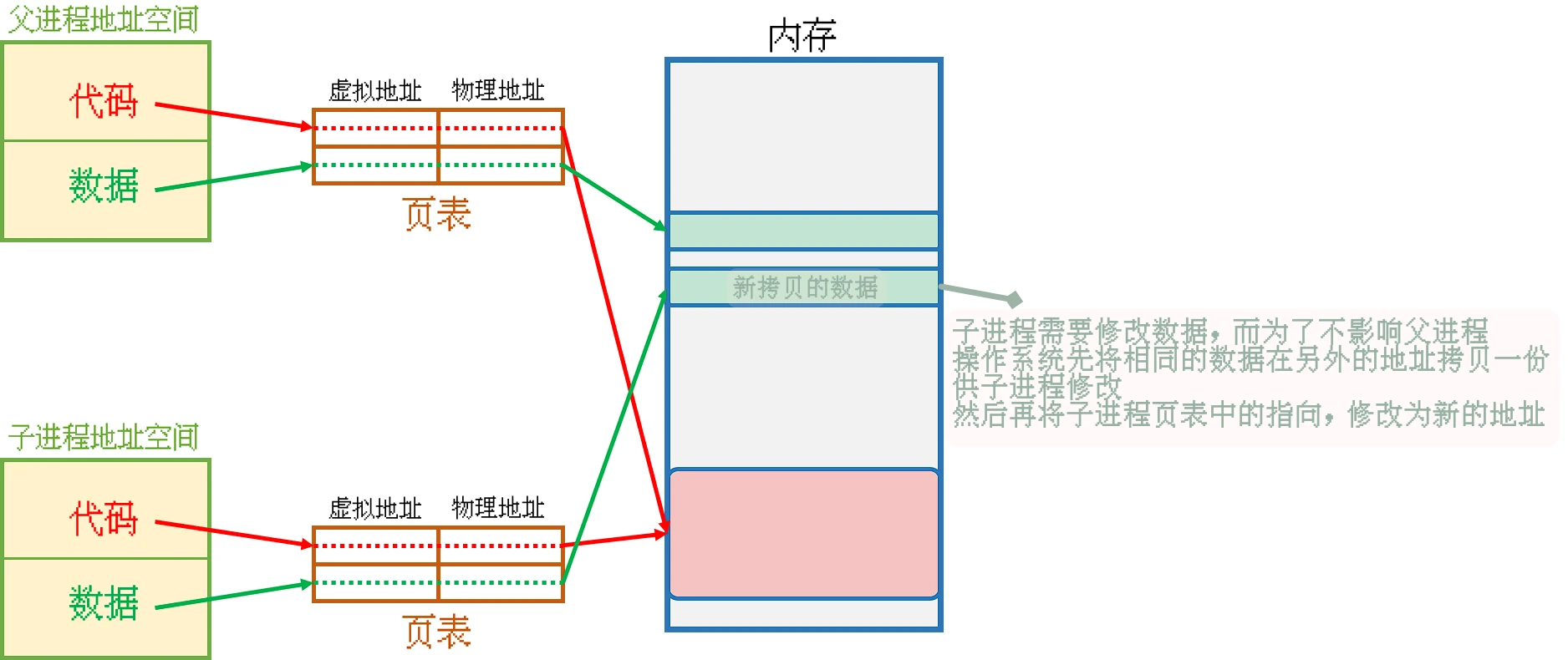
创建子进程的时候, 关于数据的拷贝最理想的情况是什么? 一定是在创建子进程的时候,
就只将父子进程需要修改的数据拷贝一份.但是, 这样的做法从技术的角度来讲, 是很复杂的, 至少相对于写时拷贝来讲, 是非常复杂的
-
如果在创建子进程的时候, 就执行数据和代码的拷贝工作, 那
是否给fork()这个原本只是为了创建子进程而诞生的系统调用增加了一定的成本?无论是从内存还是从时间的成本上. 毕竟fork()在执行结束的时候子进程已经创建完成了, 也就是说在创建子进程的时候执行拷贝工作, 其实一定是交给fork()来做的.
写时拷贝就是由操作系统的内存管理模块完成的
fork()也可能创建子进程失败
再识进程终止
X(dead)状态正确认识进程终止
main()函数是进程的入口函数return 值; 语句返回一个值. 普通函数的返回值 可以由我们来主动接收, 也就是说普通函数的返回值其实可以看作是返回给程序中的变量的.main()函数的返回值是返回给谁的呢?而且, 在学习C/C++过程中, 好像main()函数的返回值一直是0, 可以是其它值吗?- 代码正常跑完, 进程结果正确
- 代码正常跑完, 进程结果错误
- 代码没有跑完, 进程异常退出
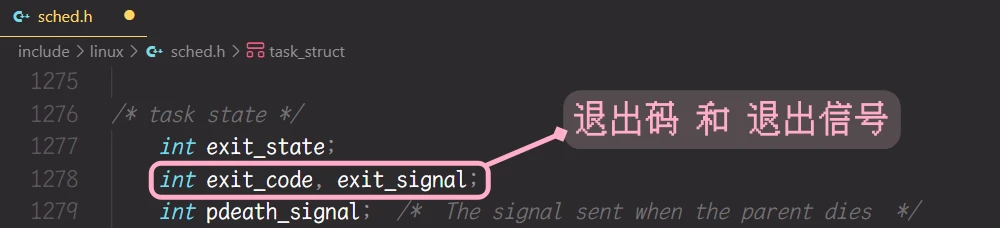
main()函数的返回值, 就是用来判断进程的结果的.main()函数的返回值其实说明了进程的执行结果.Z状态被称为僵尸状态, 此状态是为了维护进程的退出信息而存在的. 并且也在文章中说过, 进程的退出信息其实就是进程执行任务的结果, 并且进程的退出信息是为了让此进程的父进程接收的.进程的main()函数的返回值 其实是为了返回给父进程的**, 而 main() 函数的返回值, 我们也称之为 进程的退出码, 此退出码被描述在进程的PCB中, 也就是Linux中的task_struct中: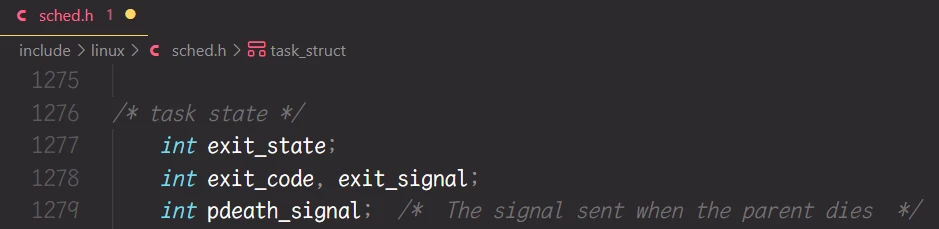
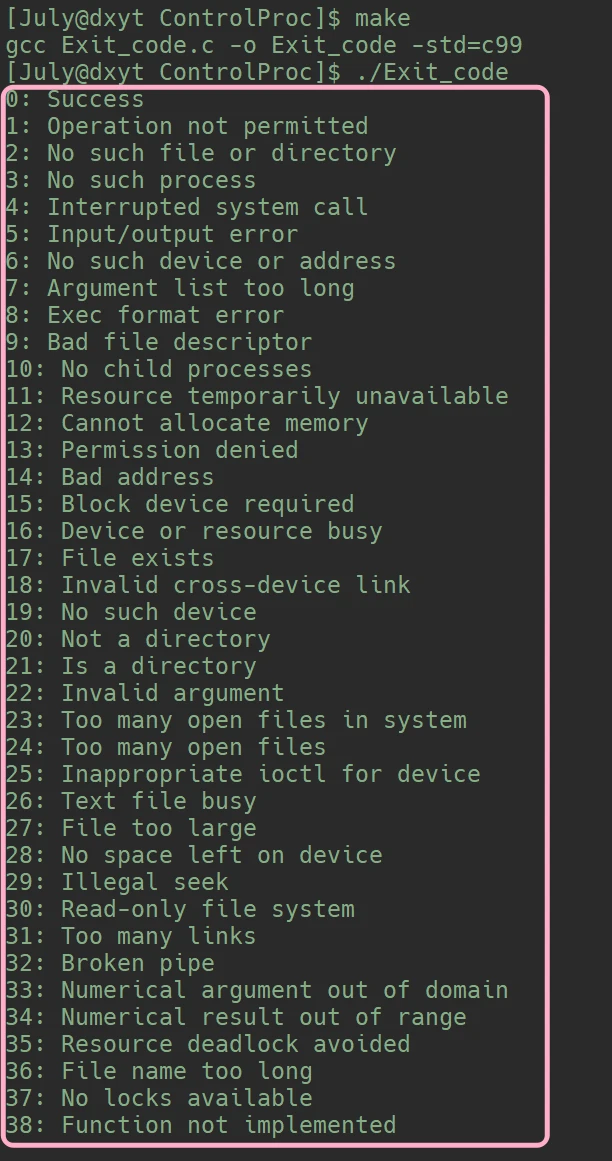
就像普通函数的返回值在main()函数中被接收一样, 在main()函数中可以编写指定的代码对函数返回值进行对比, 进而判断出普通函数的执行结果父进程接收子进程的退出码, 父进程代码中或许就存在关于子进程退出码的判断.main()函数的非0返回值 以及其意义、原因, 可以由用户自定义在Linux中针对进程的不同退出码有不同的解释:
在程序中打印 字符串函数strerror(i) 的值, 就可以将Linux系统认为的退出码的意义打印出来
查看进程的退出码
echo $?, 这个指令可以在命令行中输出上一个推出的进程的退出码: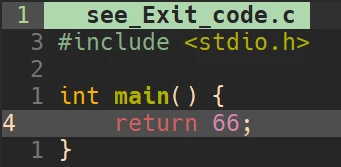
echo $? 就可以查看到退出码: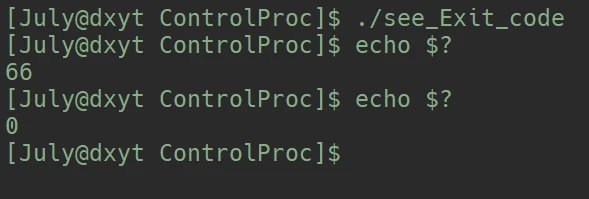
echo $? 显示了上一个退出进程的退出码66echo $? 现实的退出码就是0了呢?echo $? 时, 上一个退出的进程其实是 第一个echo $?, 而第一个echo $?正常执行成功了, 所以其退出码是0exit() 和 _exit() 退出进程
在mian()函数中执行return语句才能进程退出, 是因为非main()函数执行return就只是函数的返回值, 是被其他变量等接收的在代码中的任何位置调用exit()或_exit()函数来退出进程exit()的头文件是
stdlib.h, 而 _exit()的头文件则是unistd.h
exit():可以在代码的任意位置使用, 使进程退出, 且exit()的参数即为进程的退出码: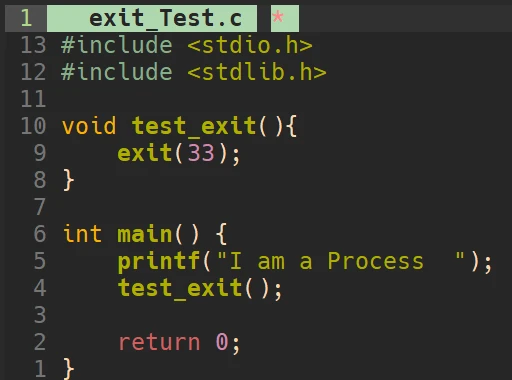

_exit():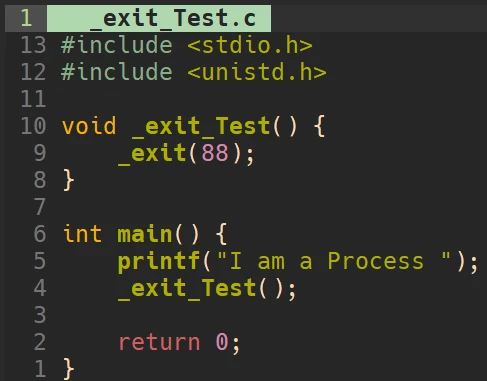
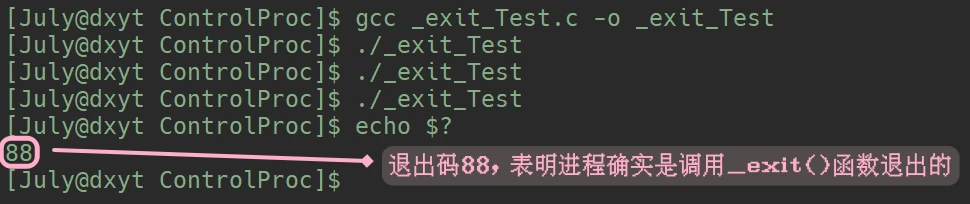
'\n'直接刷新缓冲区. 而调用exit()时, printf()函数正常打印出来了, 调用_exit()时却什么都没有打印.exit()在执行时会先刷新进程的缓冲区, 而_exit()并不会其实, exit()函数内部, 调用了_exit()函数
进程等待
父进程回收子进程退出信息的动作叫做等待, 即 如果父进程不等待子进程, 那么子进程将一直是僵尸进程内存泄漏问题等待方法

-
wait()
wait()系统调用
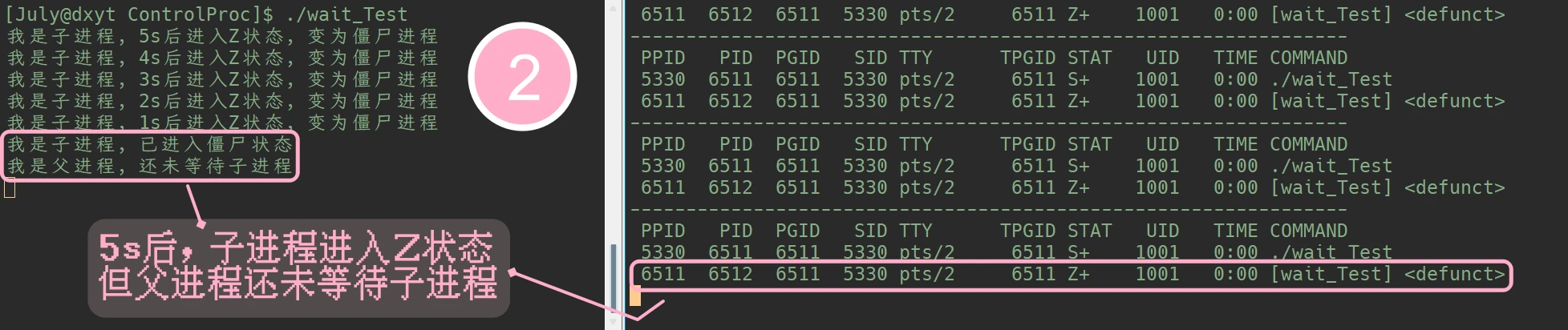
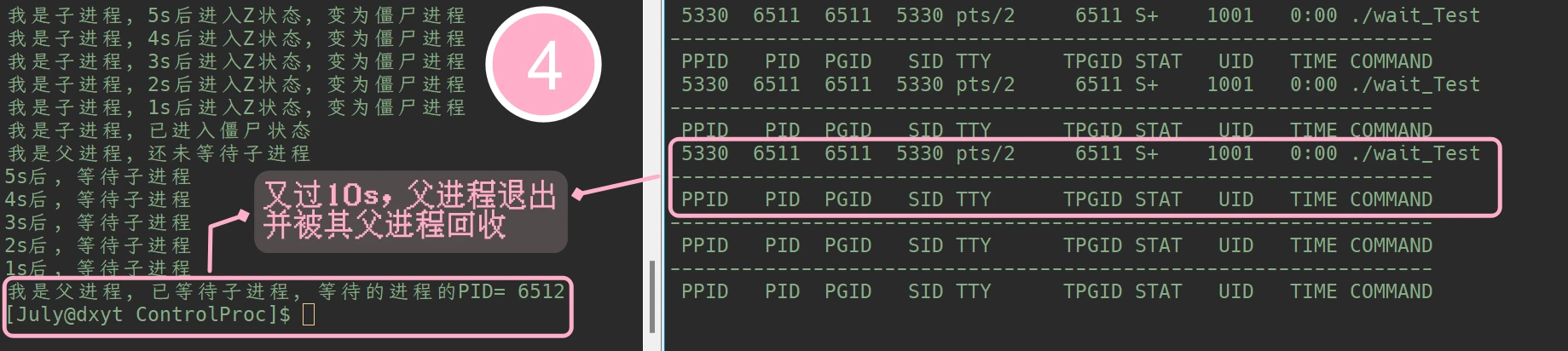
会等待任意一个退出的子进程(暂时不考虑wait()的参数, 在介绍waitpid()时再介绍这个指针参数):#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/types.h> #include <sys/wait.h> int main() { pid_t id = fork(); if (id == 0) { int cnt = 5; while (cnt) { printf("我是子进程, %ds后进入Z状态, 变为僵尸进程\n", cnt); sleep(1); cnt--; } printf("我是子进程, 已进入僵尸状态\n"); exit(123); } else { sleep(6); printf("我是父进程, 还未等待子进程\n"); sleep(19); int cnt = 5; while (cnt) { printf("%ds后, 等待子进程\n", cnt); cnt--; sleep(1); } pid_t waitPid = wait(NULL); printf("我是父进程, 已等待子进程, 等待的进程的PID= %d\n", waitPid); sleep(10); // 父进程等待子进程之后, 先不要结束, 便于观察现象 } return 0; }while :; do ps ajx | head -1 && ps ajx |grep wait_Test |grep -v grep; sleep 1; echo "----------------------------------------------------------------"; done #BR/#
此命令行指令, 是
一个简单的指定进程的观测指令, 每1s打印一次所查找进程的相关信息此代码执行之后, 配合进程观测指令, 可以看到的结果是:
![1]() 1
1![2]() 2
2![3]() 3
3![4]() 4
4此代码, 可以看到子进程被创建, 子进程进入僵尸状态, 父进程等待子进程, 父进程退出的整个流程
可以看到, 我们使用waitPid变量接收了wait()的返回值, 然后输出. 可以发现
wait()系统调用的返回值, 即为其等待的子进程的PID. -
waitpid()
与
wait(int *status)不同,waitpid(pid_t pid, int *status, int options)有三个参数, 其返回值与wait()相同,若返回值 > 0 返回值即为等待的子进程的PID; 若返回值 = -1, 即为调用失败, errorno会被设置为错误提示码; 若返回值 = 0, 则表示没有已退出的子进程可回收(此种情况的出现, 需要设置)首先, 先介绍waitpid()三个参数的含义:
-
pid_t pid其实看到pid这个变量 就应该可以猜到此参数的意义.
此参数可以传入的是子进程的pid, 意为指定pid让父进程等待, 即 父进程等待指定的子进程当此参数传入
-1时, waitpid()的作用 <=> wait(), 也是等待任意的子进程当此参数传入其他值时, 那么此值就表示某个pid, waitpid()的作用就是等待传入的此pid的子进程
-
int *statuswait()仅有的一个参数也是这个参数, 那么这个参数的意义是什么?
status这个参数是一个指针参数, 也是一个
输出型参数.输出型参数是什么意思?输出型参数意味着, 此参数其实
是向外部传递信息的, 当 waitpid()此函数等待到一个退出的子进程的时候,子进程的退出信息会被存储到 status指针指向的内容中子进程的退出信息不就是退出码吗?并不全是, 之前提到过进程的退出信息也是在 task_struct中存储着呢:
![]()
也就是说,
status指向的内容中不仅存储了退出码, 还存储了退出信号. 退出码我们知道是什么, 而退出信号又是什么?在上面我们提到过, 一个进程退出时应该有三种情况:
- 代码正常跑完, 结果正确
- 代码正常跑完, 结果不正确
- 代码没有跑完, 进程异常退出
前两种情况我们已经分析过了, 那么第三种情况 进程异常退出, 进程为什么会异常退出呢?
其实,
进程异常退出的原因是进程收到了某种信号, 就类似 kill -9 这样的命令 其实就是一种信号进程信号这里不做介绍, 只需要知道进程异常退出是收到了某种信号即可
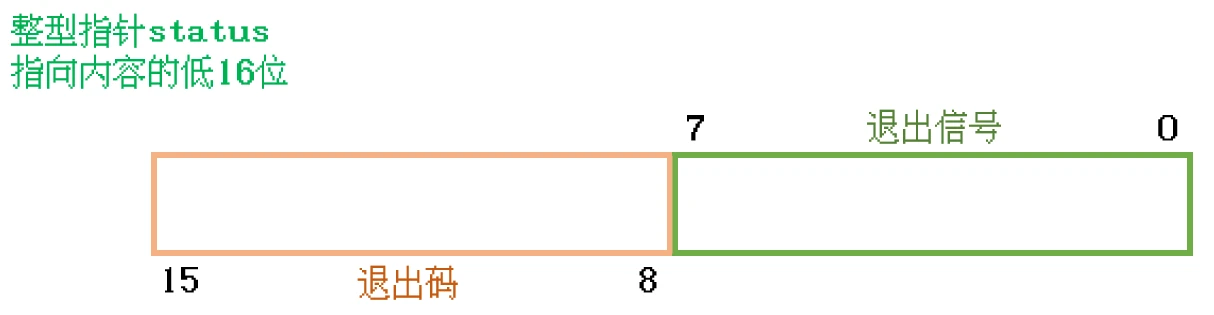
那么, 也就是说 status指向的空间, 不仅接收退出码, 还接收退出信号. 一个整型是怎么接收两个整型内容的呢?
其实 status指针指向的是一个整型, 而这个整型只需要关注
低16位就可以了,此低16位中的高8位 用来表示退出码, 低8位 用来表示退出信号:![]()
也就是说,
waitpid()使用时第二个参数需传入一个int类型变量的地址, 当waitpid()等待到一个子进程之后, 传入的地址所指向的变量的低16位中, 低八位表示子进程的退出信号, 高八位表示子进程退出码并且,
当子进程是正常退出时, 表示退出信号的八位为0; 当子进程被某种进程信号所杀时, 表示退出码的八位为0.举个例子:
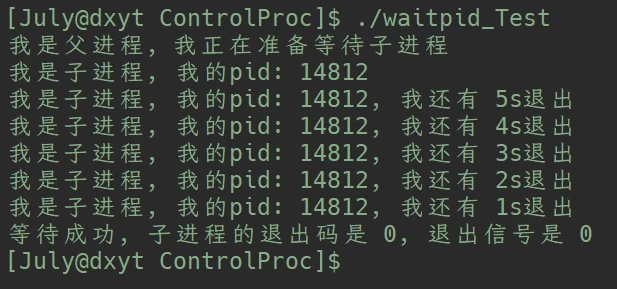
就以这段代码作为展示:
#include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/wait.h> int main() { pid_t id = fork(); if (id == 0) { printf("我是子进程, 我的pid: %d\n", getpid()); sleep(10); } else { printf("我是父进程, 我正在准备等待子进程\n"); int status = 0; pid_t pidGet = waitpid(id, &status, 0); if (pidGet > 0) printf("等待成功, 子进程的退出码是 %d, 退出信号是 %d\n", (status >> 8) & 0xFF, status & 0x7F); } return 0; }这段代码的程序运行的时候, 子进程会被创建, 并且15s之后会return 0. 父进程会调用waitpid()阻塞等待刚刚被创建的子进程. 当父进程等待子进程成功了, 父进程会获取子进程的退出码和退出信号并打印出来.
关于
退出信号的计算, 需要status&0x7F, 是因为表示退出信号的八位, 其中最高位是一个单独的core_dump标志, 暂时忽略若此时子进程是15s后返回的return 0退出的, 那么会有什么结果呢?
![]()
而若子进程在创建之后的15s内, 被某种进程信号强制退出的话, 又会有什么结果呢?
![]()
可以看到, 父进程中的整型变量status成功接收到了子进程的退出码和退出信号.
父进程中的status变量接收到数据之后, 其实不需要通过手动位运算来计算出子进程的退出码和退出信号.
其实而可以通过两个
宏:WEXITSTATUS(status): 提取子进程退出码WERMSIG(status): 提取子进程退出信号
还有一个
宏, 可以直接用来判断子进程是否正常退出:WIFEXITED(status): 若子进程正常退出, 则为真在上面提到过一个问题, 当进程退出码为0时, 往往意味着进程正常退出.
而此时子进程接收到信号而退出, 肯定是不属于正常退出的范围的. 为什么子进程的退出码依旧是0?是否与 退出信号的9, 冲突了?
当然没有,
当退出信号不为0时, 退出码就没有意义了, 可以忽略不看 -
int options这个参数其实像是waitpid()的一个配置参数,
通过不同的传参, 可以让waitpid()有不同的工作模式当
options传入的参数为0时, waitpid()采用阻塞等待的工作模式.什么是阻塞等待?
之前我们介绍过阻塞是什么样的, 当进程在等待非CPU资源时, 我们称这种情况为进程阻塞
而当options传入0时, waitpid()的工作模式就像是阻塞一样, 如果其等待的子进程还未退出, 那么父进程就会一直阻塞等着子进程退出, 在子进程退出之前, 父进程一直处于阻塞状态, 不会做其他事情, 就只是等着子进程退出.
这个一直等着子进程退出的行为, 其实是一种等待软件资源的情况, 所以当options参数传入0时, waitpid()的工作模式可以被称为阻塞等待当
options传入的参数为WNOHANG时, waitpid()采用基于非阻塞的轮询等待方案与阻塞等待不同, 非阻塞的轮询等待方案,
不会让父进程一直处于阻塞状态当
options传入WNOHANG时, waitpid()只会当前等待一次, 如果等待时没有子进程退出需要回收, 那么waitpid()就会返回0也就是说,
options传入WNOHANG时, waitpid()只会回收当前已经退出的子进程, 如果没有子进程处于此状态, 那么waitpid()就会返回0. 在返回之后, 即使又有子进程退出了, waitpid()也不再回收所以,
在options传入WNOHANG时, waitpid()的使用一般伴随着循环. 即让waitpid()循环判断是否存在需要回收的子进程, 这样也不影响父进程做其他工作
-



进程替换
什么是进程替换?
让一个进程执行其他程序的代码, 即进程替换, 不单是子进程, 当前进程也可以发生进程替换.进程替换的原理
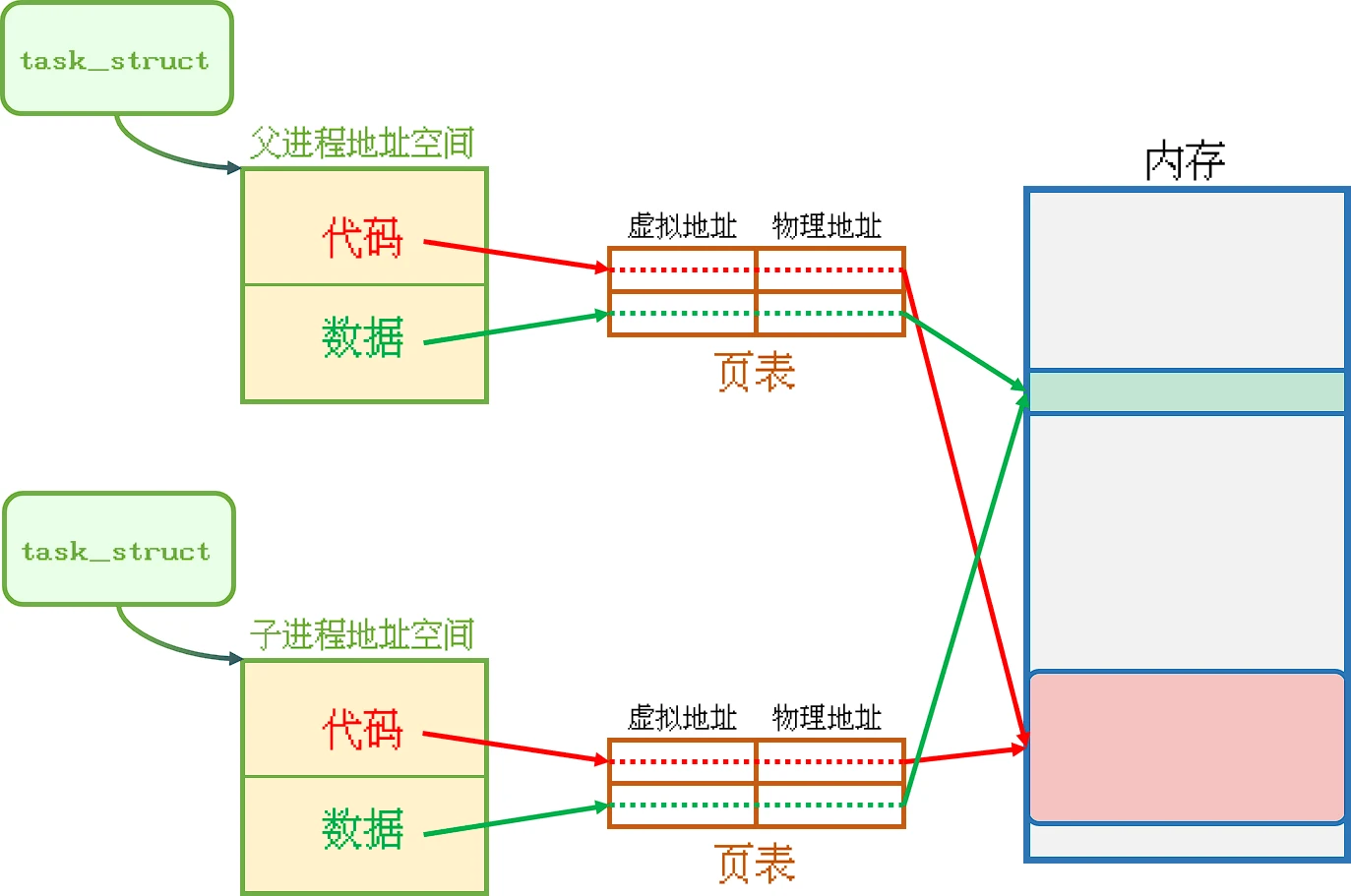
调用系统调用接口, 首先操作系统会将内存中父进程的代码和数据都拷贝一份, 然后将磁盘中的程序加载到此内存结构中.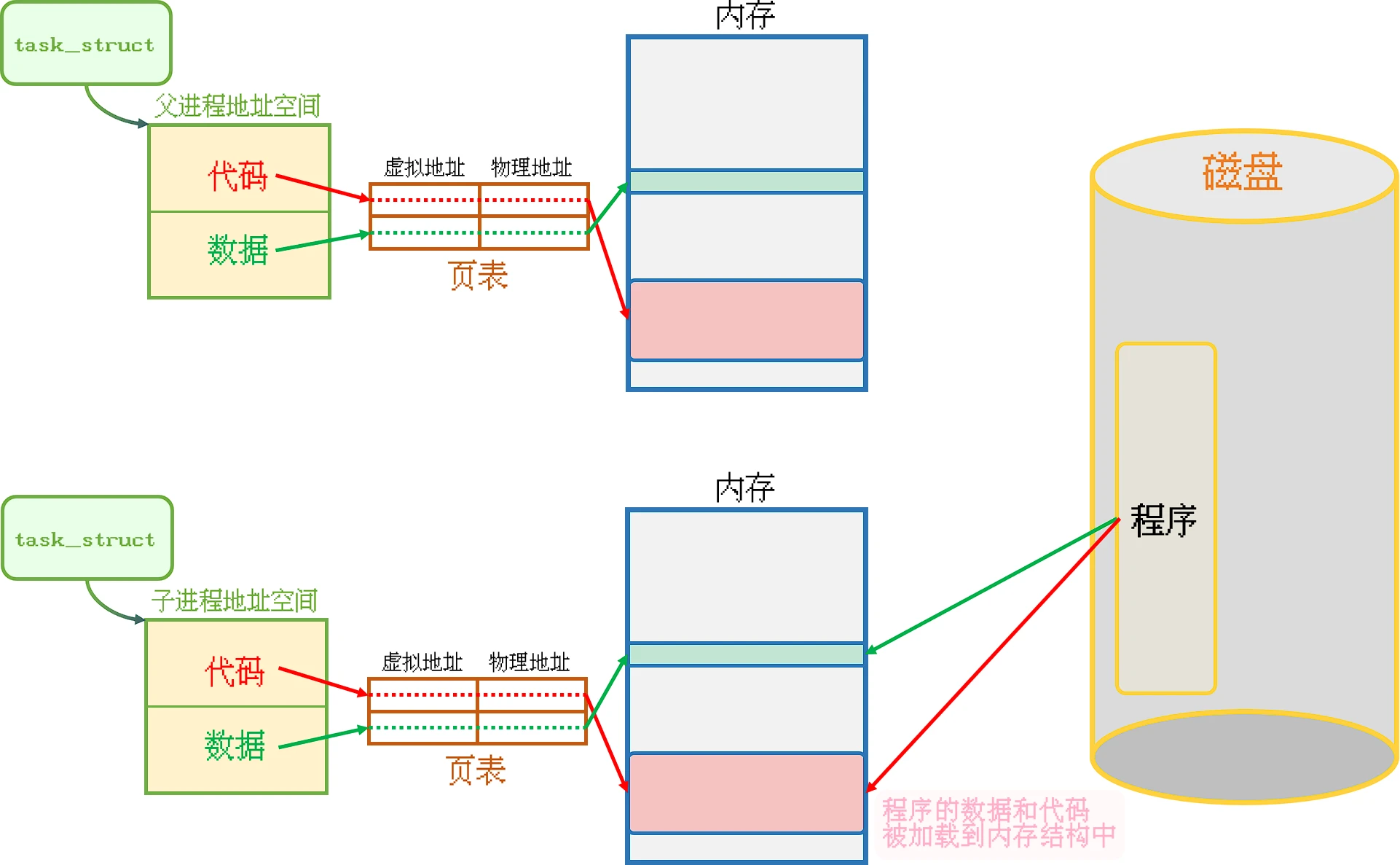
没有新的进程被创建的, 新进程被创建的标志是操作系统创建了进程的PCB和进程地址空间, 而这个过程中始终都是两个PCB和两个进程地址空间为什么要进程替换?
- 执行父进程的代码片段
- 让子进程执行磁盘种的其他程序, 其他程序可能涉及: C/C++、Java、Python、Shell等不同语言的程序
令行中执行的命令大多数都是由shell创建子进程然后再进程替换实现的如何进行进程替换?
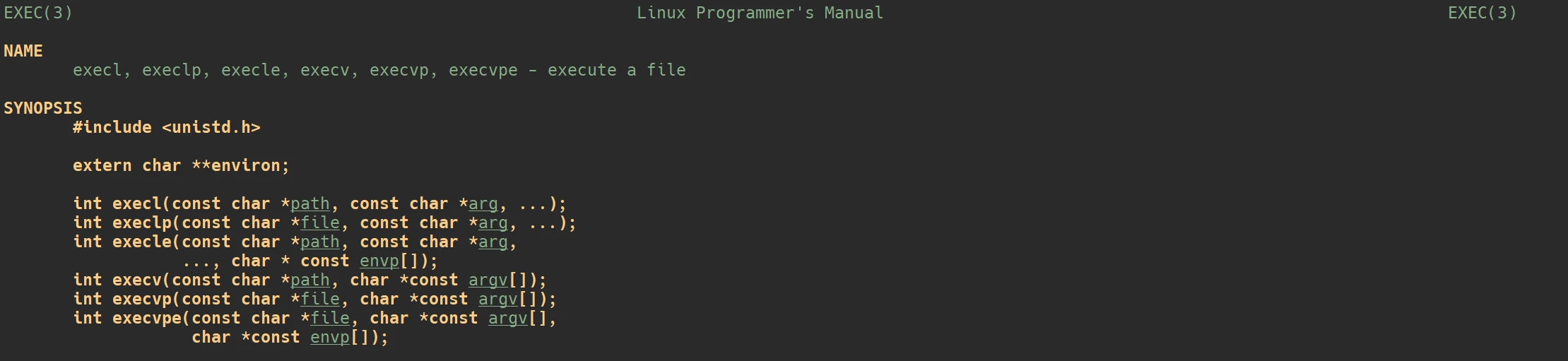
execl()
int execl(const char *path, const char *arg, ...);...
...在参数中出现
..., 表示可变参数, 即此函数的参数数量其实是不定的, 是可以动态变化的
- 程序在磁盘中的所在路径
- 程序运行所需要的携带的选项, 当然也可以选择不携带
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
pid_t id = fork();
if(id == 0) {
printf("我是子进程, pid :%d\n", getpid());
execl("/usr/bin/ls", "ls", "-l", "-a", NULL);
printf("我是子进程, pid :%d\n", getpid());
}
else {
pid_t ret = wait(NULL);
if(ret > 0) {
printf("我是父进程, 等待子进程成功\n");
}
else {
printf("等待子进程失败\n");
}
}
return 0;
}ls -l -a 的命令: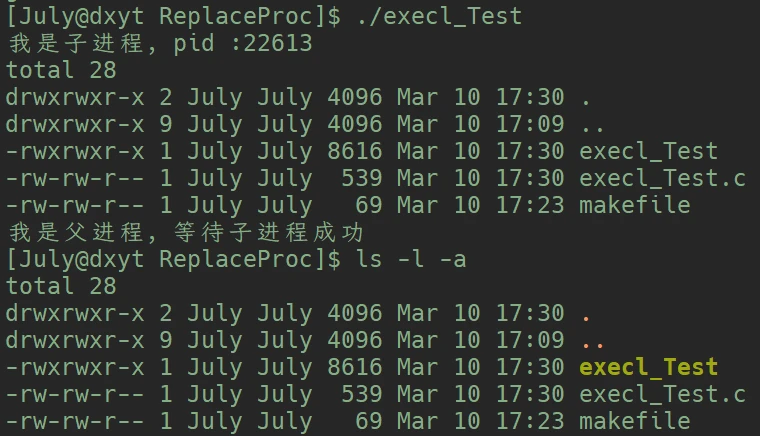
const char *path, 需传入需要替换成的程序的路径const char *arg, ..., 则表示执行程序需要携带的选项, 且传入的表示选项的参数需要以NULL结尾, 告诉函数传参结束(main()函数argv数组中便是如此)
在execl函数之后的printf并没有打印出来, 即 printf()函数并未执行:
当进程替换成功之后, 进程的所有代码和数据都已经被替换掉了, 也就意味着execl()函数之后的代码全部失效需不需要接收execl()函数的返回值, 然后判断是否替换成功?
不需要, 因为替换成功的话, execl()函数之后的代码根本不会执行, 代码和数据都已经被替换掉了. 只有替换失败的时候, 才会执行execl()之后的代码
可以直接根据进程的执行结果判断进程替换是否成功
子进程替换, 是否影响父进程?
不会影响到父进程的, 因为进程间具有独立性execv()
int execv(const char *path, char *const argv[]);path 就不用在分析了, 而第二个参数 argv 也有些熟悉#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
#define SIZE 128
int main() {
pid_t id = fork();
if(id == 0) {
char *const execv_argv[SIZE] = {
(char*)"ls",
(char*)"-l",
(char*)"-a",
NULL
};
printf("我是子进程, pid :%d\n", getpid());
execv("/usr/bin/ls", execv_argv);
printf("我是子进程, pid :%d\n", getpid());
}
else {
pid_t ret = wait(NULL);
if(ret > 0) {
printf("我是父进程, 等待子进程成功\n");
}
else {
printf("等待子进程失败\n");
}
}
return 0;
}ls -l -a相同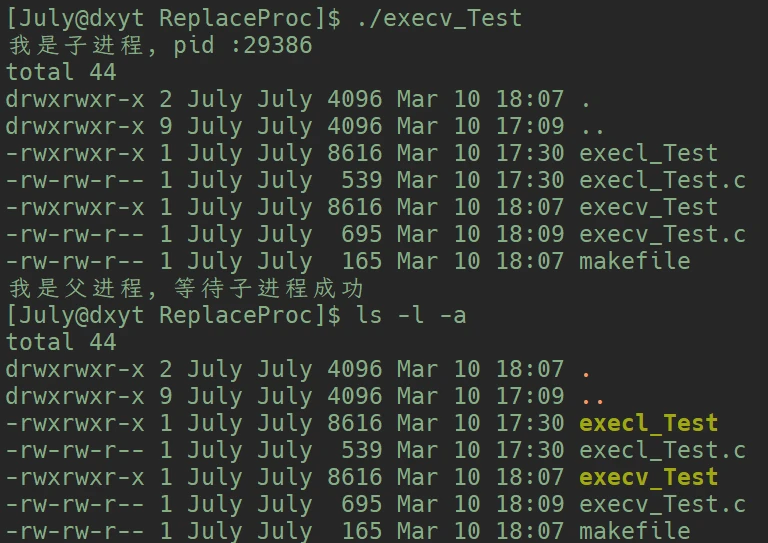
execlp()
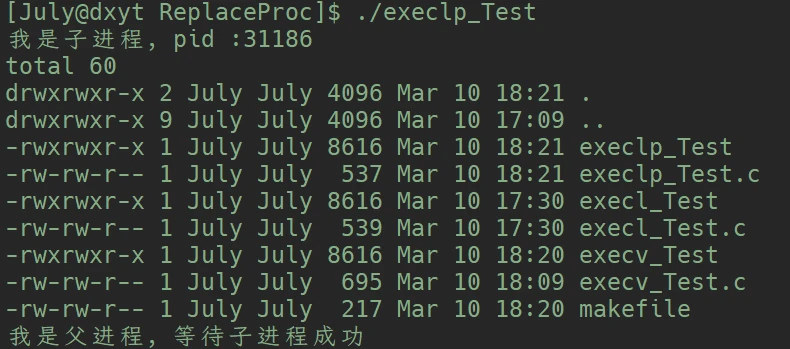
int execlp(const char *file, cosnt char *arg, ...);execl()函数有些许不同参数file, 不用添加路径, 只需要传入程序名execlp()的函数名中的p, 其实就是表示此函数可以在环境变量PATH路径下搜索命令execlp()函数传参时, 只要替换的程序在PATH的路径下, 就可以直接传程序名, 而不用传路径#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
pid_t id = fork();
if(id == 0) {
printf("我是子进程, pid :%d\n", getpid());
execlp("ls", "ls", "-l", "-a", NULL);
printf("我是子进程, pid :%d\n", getpid());
}
else {
pid_t ret = wait(NULL);
if(ret > 0) {
printf("我是父进程, 等待子进程成功\n");
}
else {
printf("等待子进程失败\n");
}
}
return 0;
}
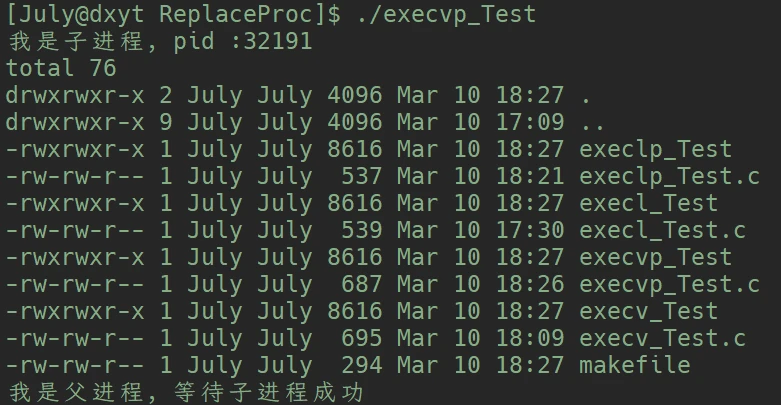
execvp()
int execvp(const char* file, char *const argv[]);file, 直接传入程序名, 此函数会在环境变量PATH的路径下搜索argv, 则是执行程序携带的选项的数组, 每个元素存储一个选项
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
#define SIZE 128
int main() {
pid_t id = fork();
if(id == 0) {
char *const execv_argv[SIZE] = {
(char*)"ls",
(char*)"-l",
(char*)"-a",
NULL
};
printf("我是子进程, pid :%d\n", getpid());
execvp("ls", execv_argv);
printf("我是子进程, pid :%d\n", getpid());
}
else {
pid_t ret = wait(NULL);
if(ret > 0) {
printf("我是父进程, 等待子进程成功\n");
}
else {
printf("等待子进程失败\n");
}
}
return 0;
}
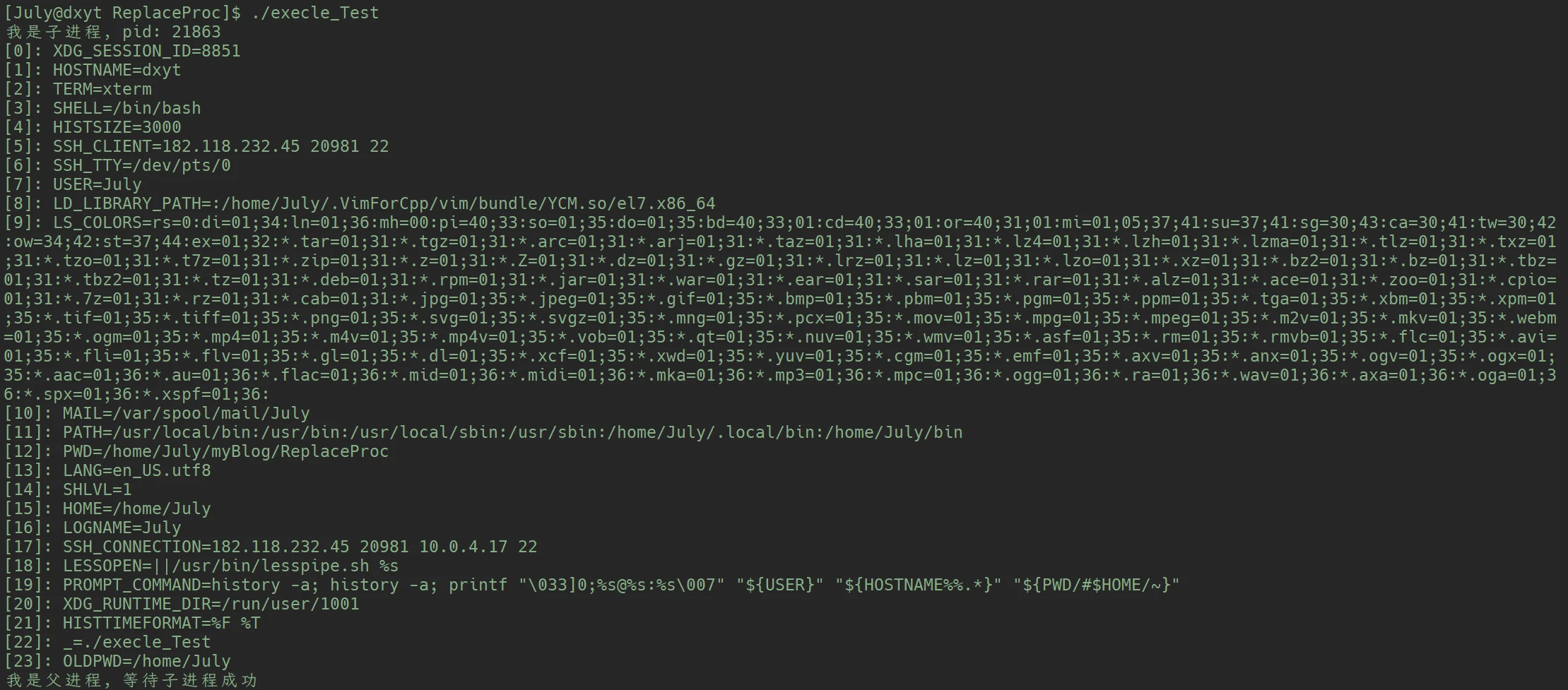
execle()
int execle(const char *path, const char* arg, ..., char *const envp[]);envp, 此参数需要传入的是环境变量列表extern char **environ 是类似的, 甚至可以说是相同的博主的Linux环境变量的相关文章:
/* 父进程代码 */
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main() {
extern char **environ;
pid_t id = fork();
if(id == 0) {
printf("我是子进程, pid: %d\n", getpid());
execle("./env_Test", "./env_Test", NULL, environ); // 替换为字节写的程序 env_Test
printf("我自己进程, pid: %d\n", getpid());
}
else {
pid_t ret = wait(NULL);
if(ret > 0) {
printf("我是父进程, 等待子进程成功\n");
}
}
return 0;
}
/* env_Test 代码 */
// 要将下面代码 编译为 env_Test 文件
#include <stdio.h>
int main() {
extern char **environ;
for(int i = 0; environ[i]; i++) {
printf("[%d]: %s\n", i, environ[i]);
}
return 0;
}
environ环境变量列表传入了env_Test子进程中env_Test 也会打印这些内容的: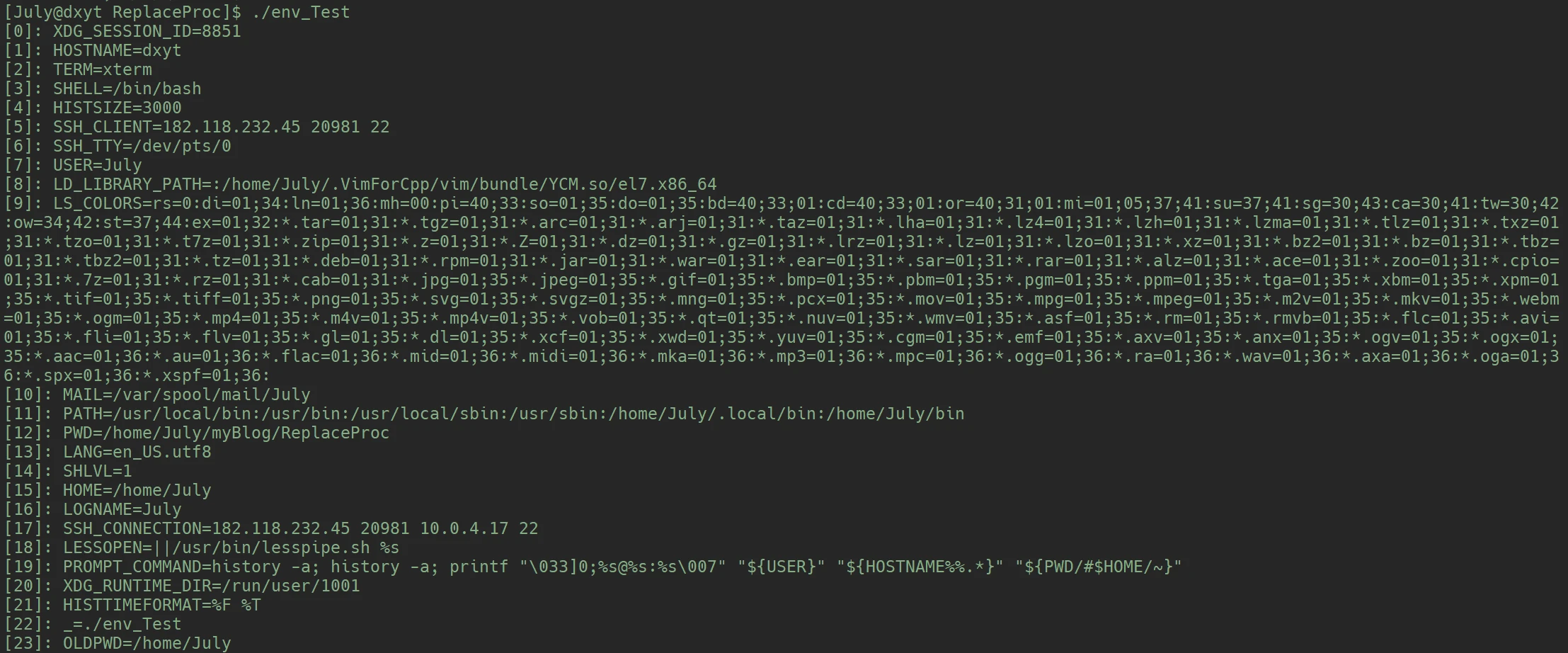
这其实是因为, 使用execle()函数将子进程替换为
env_Test进程, 传入的环境变量其实是父进程的环境变量列表environ, 那么execle执行的env_Test也就打印了父进程的环境变量
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main() {
// 自定义一个char* 数组, 作为一个自定义环境变量列表
char *const envp[] = {
(char*)"MYENV1=DIY_ENV1",
(char*)"MYENV2=DIY_ENV2",
NULL
};
pid_t id = fork();
if(id == 0) {
printf("我是子进程, pid: %d\n", getpid());
execle("./env_Test", "./env_Test", NULL, envp); // 传入envp
printf("我自己进程, pid: %d\n", getpid());
}
else {
pid_t ret = wait(NULL);
if(ret > 0) {
printf("我是父进程, 等待子进程成功\n");
}
}
return 0;
}env_Test 的代码, 再执行上面这个代码时: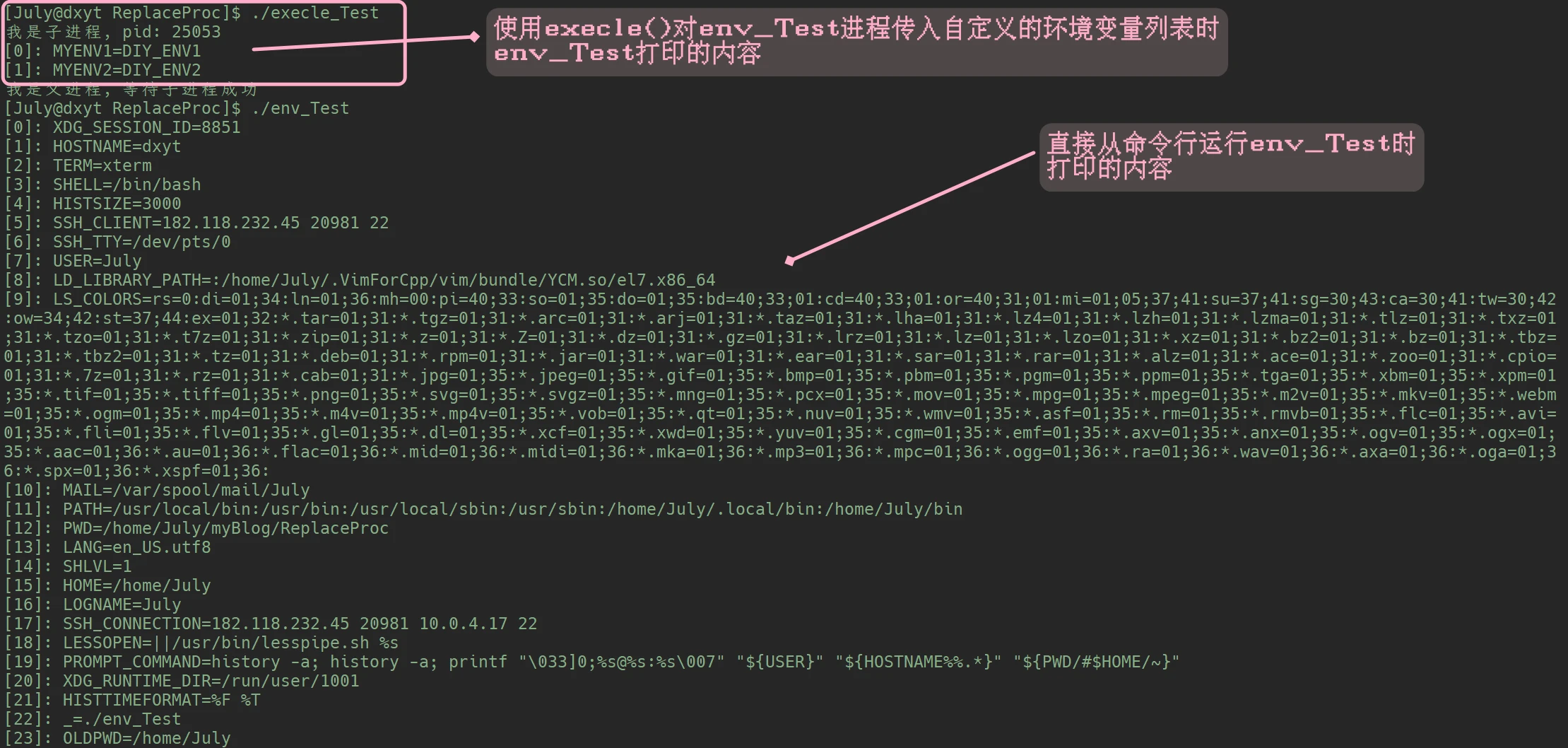
envp参数的作用是, 接收从父进程传来的环境变量列表是否就是在创建子进程时, 父进程的环境变量列表传入了子进程, 从而说子进程的环境变量继承于父进程?使用execle()函数进程替换时, 子进程的环境变量, 其实完全取决于父进程传什么环境变量列表其他不带envp参数的进程替换接口,
默认给替换的进程传入此进程的环境变量列表的即在调用
execl()execv()execlp()execvp()这些接口进程替换时,被替换到内存中的进程 默认接受的是被替换掉的进程的环境变量列表
如何在父进程的环境变量的基础上添加新的环境变量并传给子进程
putenv()
getenv()系统调用
在参数中传入需要在环境变量中添加的环境变量就可以了:#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main() {
extern char **environ;
putenv((char*)"MYENV=DIY_ENV111111111111111111111111111111111111111111111");
pid_t id = fork();
if(id == 0) {
printf("我是子进程, pid: %d\n", getpid());
execle("./env_Test", "./env_Test", NULL, environ);
printf("我自己进程, pid: %d\n", getpid());
}
else {
pid_t ret = wait(NULL);
if(ret > 0) {
printf("我是父进程, 等待子进程成功\n");
}
}
return 0;
}传入需要添加的环境变量, 就可以在进程原环境变量列表中添加一个环境变量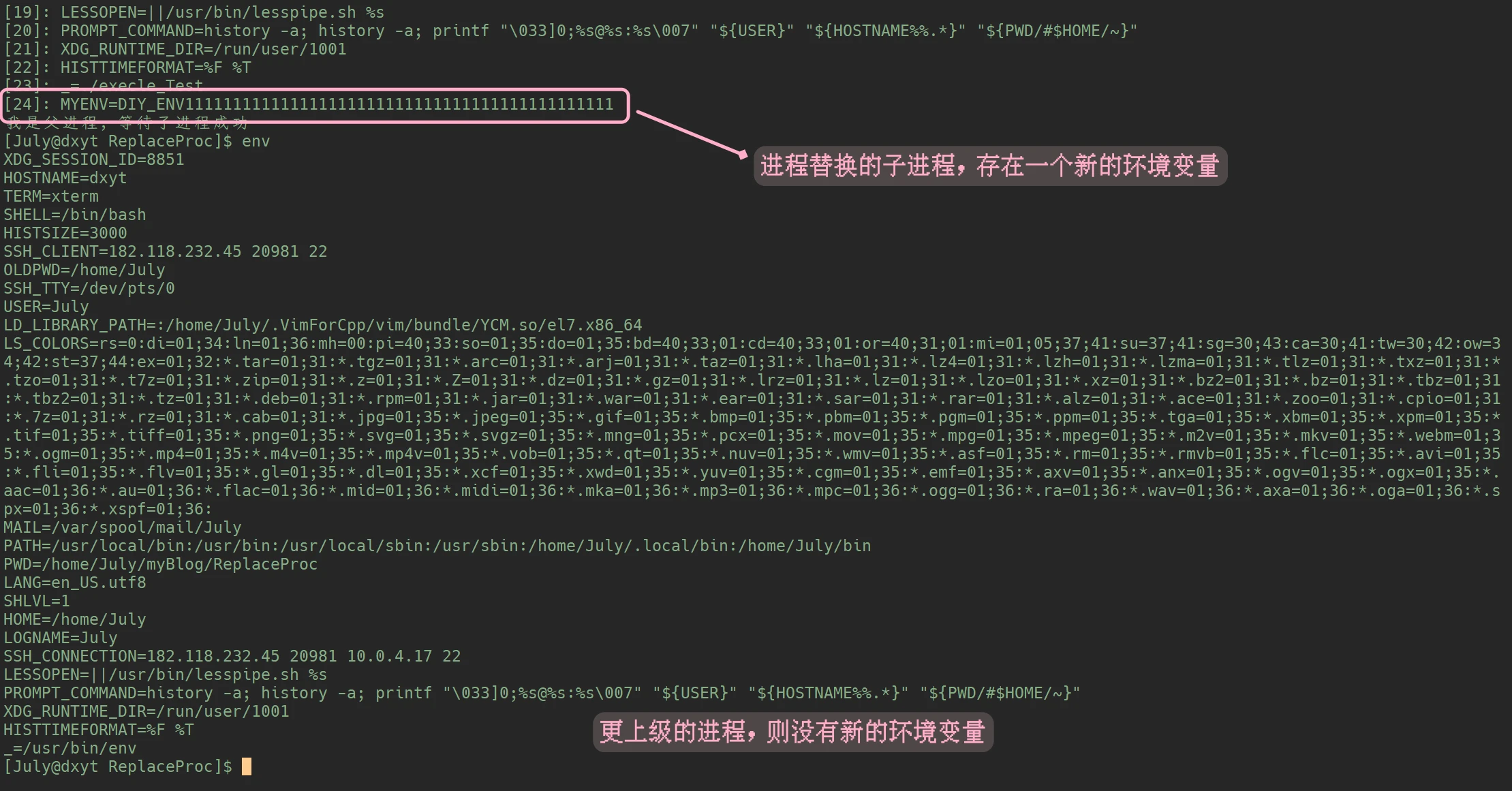
execvpe()
int execvpe(const char *file, char *const argv[], char *const envp[]);file, 传入文件名, 不需要带路径, 只需要确保文件处于环境变量PATH的路径下argv, 传入命令及携带选项的数组, 每个元素为一个命令或一个选项envp, 传入环境变量列表, 表示将此环境变量列表继承给替换的进程
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#define SIZE 128
int main() {
extern char **environ;
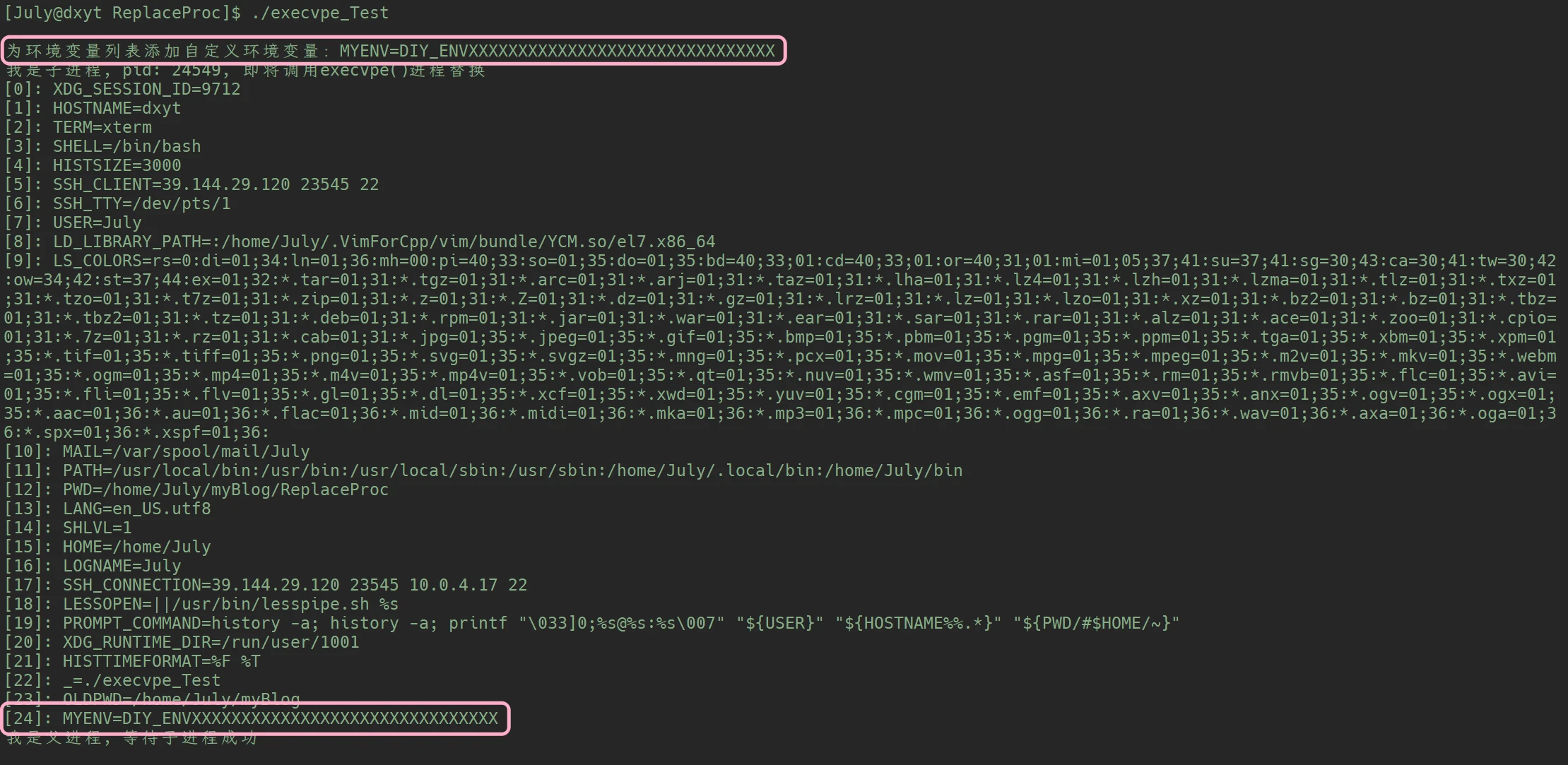
printf("\n为环境变量列表添加自定义环境变量: MYENV=DIY_ENVXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX\n");
putenv((char*)"MYENV=DIY_ENVXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX");
pid_t id = fork();
if(id == 0) {
char *const execvpe_argv[SIZE] = { (char*)"./env_Test", NULL };
printf("我是子进程, pid: %d, 即将调用execvpe()进程替换\n", getpid());
execvpe("./env_Test", execvpe_argv, environ);
printf("我是子进程, pid: %d, 进程替换失败\n", getpid());
}
else {
pid_t ret = wait(NULL);
if(ret > 0) {
printf("我是父进程, 等待子进程成功\n\n");
}
}
return 0;
}
经过介绍这6个接口, 为方便记忆其实可以将接口名中的字母赋予一定的意义:
l, list, 表示参数采用列表的方式传参v, vector, 表示参数采用数组的方式传参p, path, 表示会自动在PATH环境变量的路径下搜索命令e, env, 表示需要传入环境变量列表进而手动维护替换进程的环境变量
execve() *
单独列出来的:
int execve(const char *filename, char *const argv[], char *const envp[]);p, 说明传入程序名时, 需要传入完整的路径其他六个接口内部都会调用此接口, 此接口才是真正的系统调用接口filename, 带路径的文件名argv, 命令及携带选项的数组, 每个元素为一个命令或一个选项envp, 环境变量列表, 表示将此环境变量列表继承给替换的进程
看到这三个参数之后, 其实就可以发现为什么之前的6个之中没有
execlpe()接口
*扩展: 如何使用makefile编译生成多个不同的可执行文件
默认只会执行第一行的所描述的目标文件的依赖方法:

让make执行多个不同目标文件的依赖方法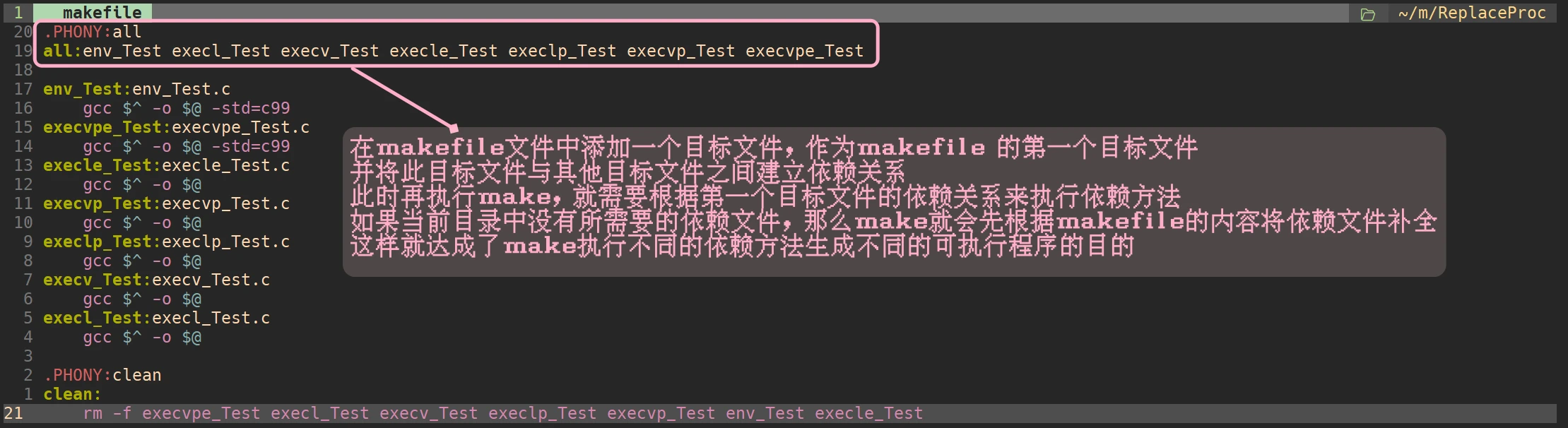
作者: 哈米d1ch 发表日期:2023 年 3 月 7 日