[Linux-IO] 五种IO模型介绍(1): 理解IO、五种IO模型的概念、
重新理解IO
Linux系统中, 使用文件IO相关的系统调用对文件描述符操作时, 比如read()、recv()或recvfrom(), 默认是阻塞模式的read()、recv()或recvfrom()会阻塞等待, 直到可以读取到数据时, read()和recv()才能将数据从内核拷贝到用户空间中fifoServer.cc#include <iostream>
#include <cstring>
#include <cerrno>
#include <sys/wait.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define IPC_PATH "./.fifo" // 命名文件路径
using std::cerr;
using std::cout;
using std::endl;
int main() {
umask(0);
if (mkfifo(IPC_PATH, 0666) != 0) {
cerr << "mkfifo error" << endl;
return 1;
}
int pipeFd = open(IPC_PATH, O_RDONLY);
if (pipeFd < 0) {
cerr << "open error" << endl;
return 2;
}
cout << "命名管道文件, 已创建, 已打开" << endl;
char buffer[1024];
while (true) {
cout << "阻塞" << endl;
ssize_t ret = read(pipeFd, buffer, sizeof(buffer) - 1);
cout << "阻塞结束" << endl;
buffer[ret] = 0;
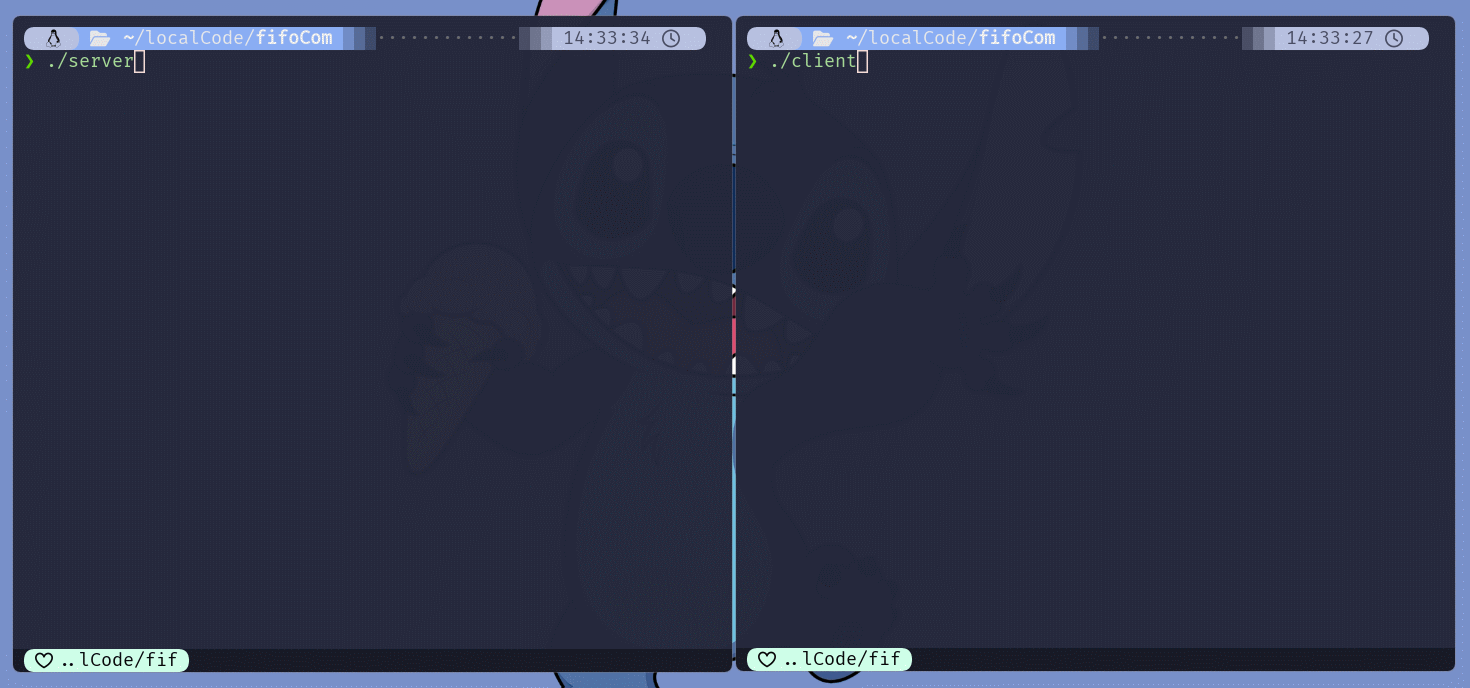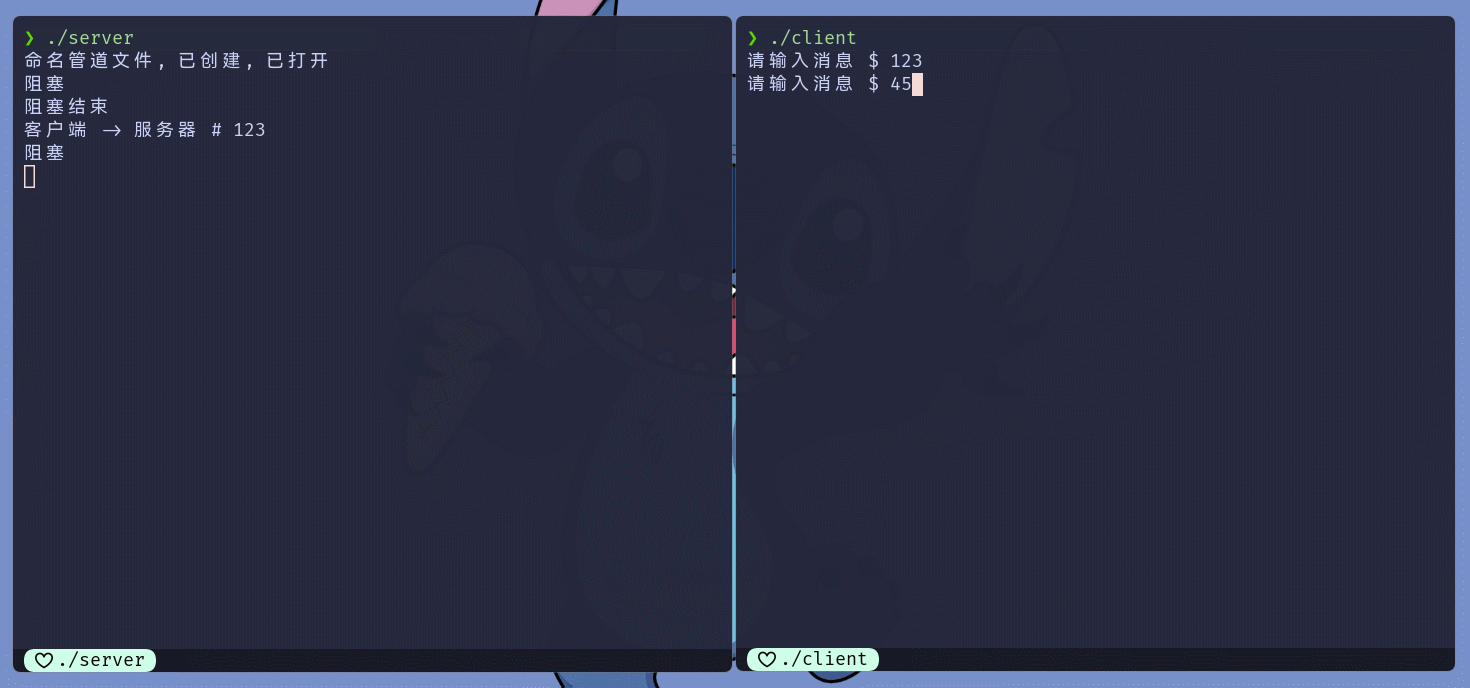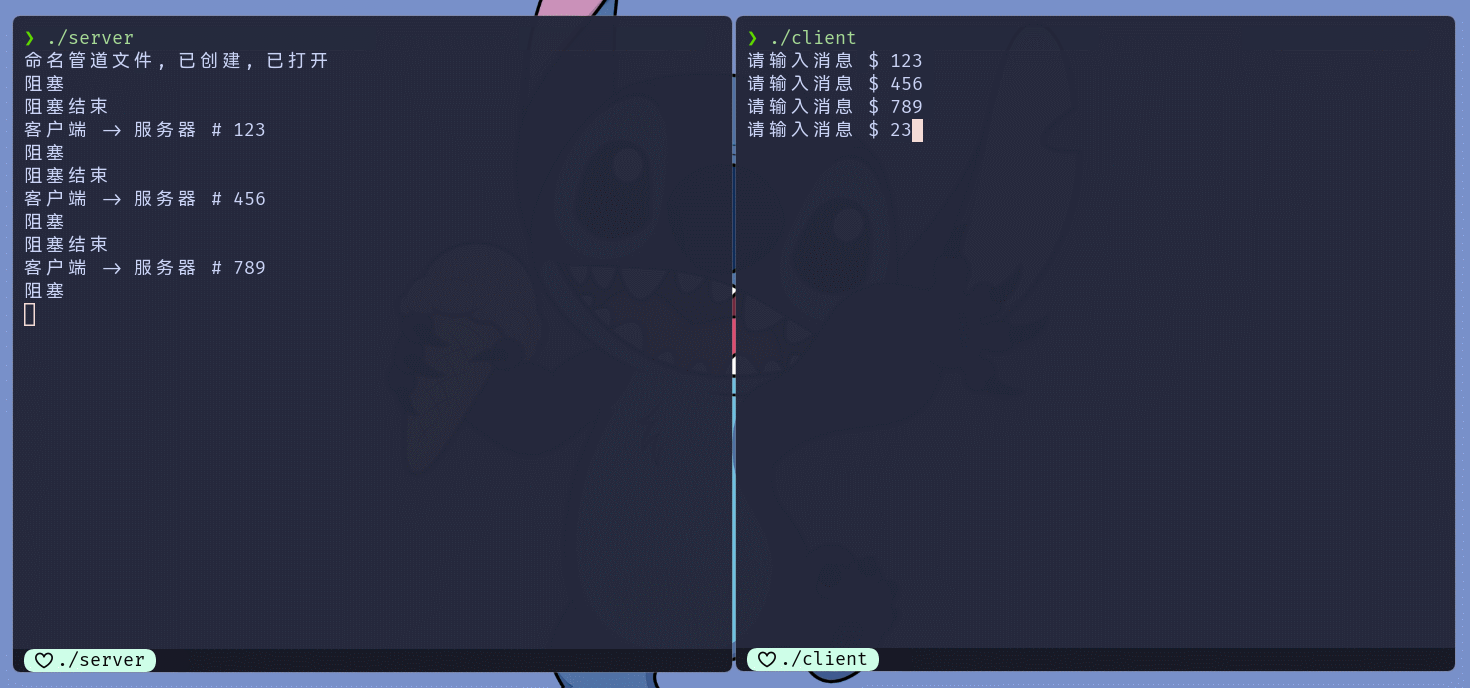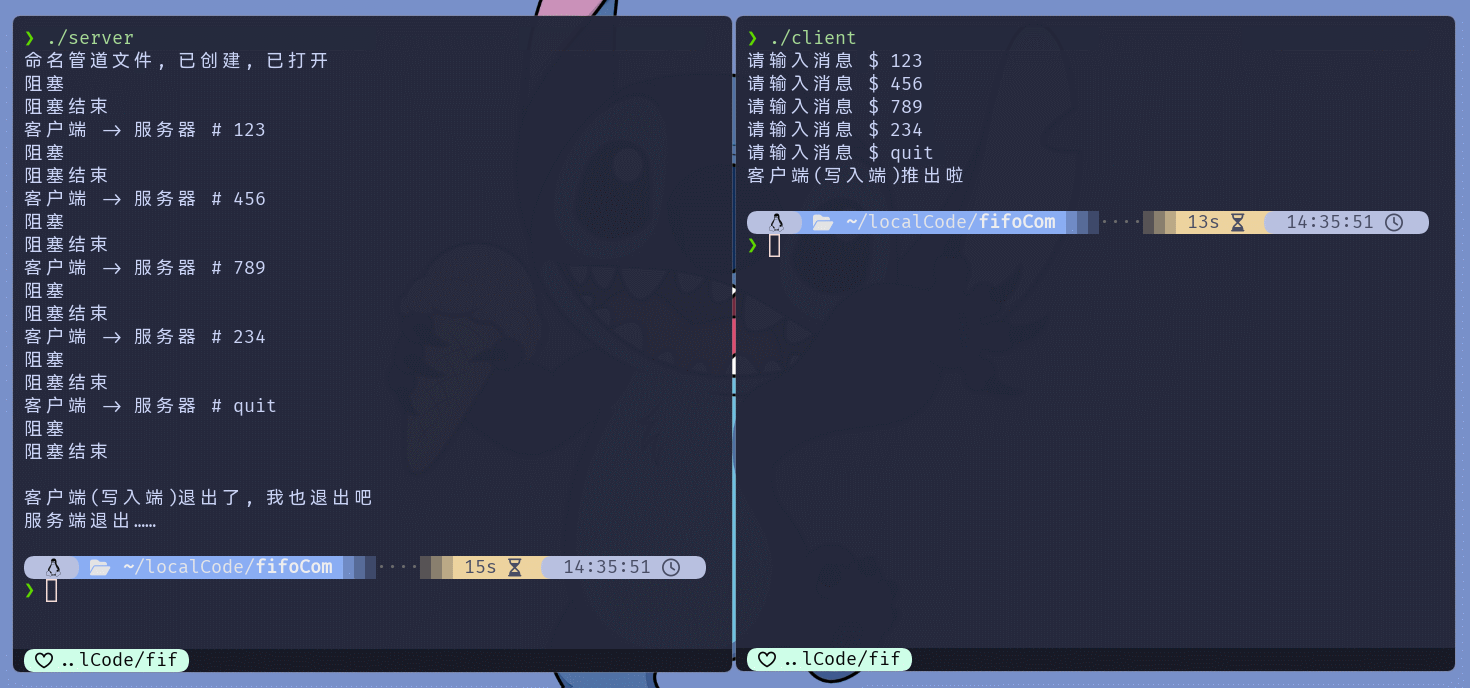
if (ret == 0) {
cout << "\n客户端(写入端)退出了, 我也退出吧";
break;
}
else if (ret > 0) {
cout << "客户端 -> 服务器 # " << buffer << endl;
}
else {
cout << "read error: " << strerror(errno) << endl;
break;
}
}
close(pipeFd);
cout << "\n服务端退出……" << endl;
unlink(IPC_PATH);
return 0;
}fifoClient.cc#include <cstdio>
#include <cstring>
#include <fcntl.h>
#include <iostream>
#include <sys/stat.h>
#include <sys/wait.h>
#include <unistd.h>
#define IPC_PATH "./.fifo" // 命名文件路径
using std::cerr;
using std::cout;
using std::endl;
int main() {
int pipeFd = open(IPC_PATH, O_WRONLY); // 只写打开命名管道, 不参与创建
if (pipeFd < 0) {
cerr << "open fifo error" << endl;
return 1;
}
char line[1024]; // 用于接收命令行的信息
while (true) {
printf("请输入消息 $ ");
fflush(stdout); // printf没有刷新stdout, 所以手动刷新
memset(line, 0, sizeof(line));
if (fgets(line, sizeof(line), stdin) != nullptr) {
// 由于fgets 会接收 回车, 所以将 line的最后一位有效字符设置为 '\0'
line[strlen(line) - 1] = '\0';
// 向命名管道写入信息
write(pipeFd, line, strlen(line));
if (strcmp(line, "quit") == 0)
break;
}
else {
break;
}
}
close(pipeFd);
cout << "客户端(写入端)退出啦" << endl;
return 0;
}
pipeFd数据 处于阻塞状态read()能够从pipeFd中读取数据, 就结束阻塞write()等一系列写操作的系统调用也是一样的, 当管道满了无法继续写入, 就会陷入阻塞, 直到管道不满才会继续写入IO操作:IO操作, 实际由阻塞 和 拷贝数据两个状态组成 (read()、write()等的本质, 是将数据在内核和用户之间进行拷贝)IO事件就绪, 拷贝数据, 就是将数据从内核或用户空间拷贝出来IO操作, 大多数情况下处于阻塞状态的时间占比更长IO效率 从思路上看不难, 减少阻塞时间就好了IO效率, 就是IO模型的作用五种IO模型
IO模型: 阻塞IO 非阻塞IO 信号驱动IO 多路转接IO(多路复用) 异步IOIO模型概念
阻塞IO
IO是最常见的IO模型IO. Linux进程所有的文件描述符默认都是阻塞的IO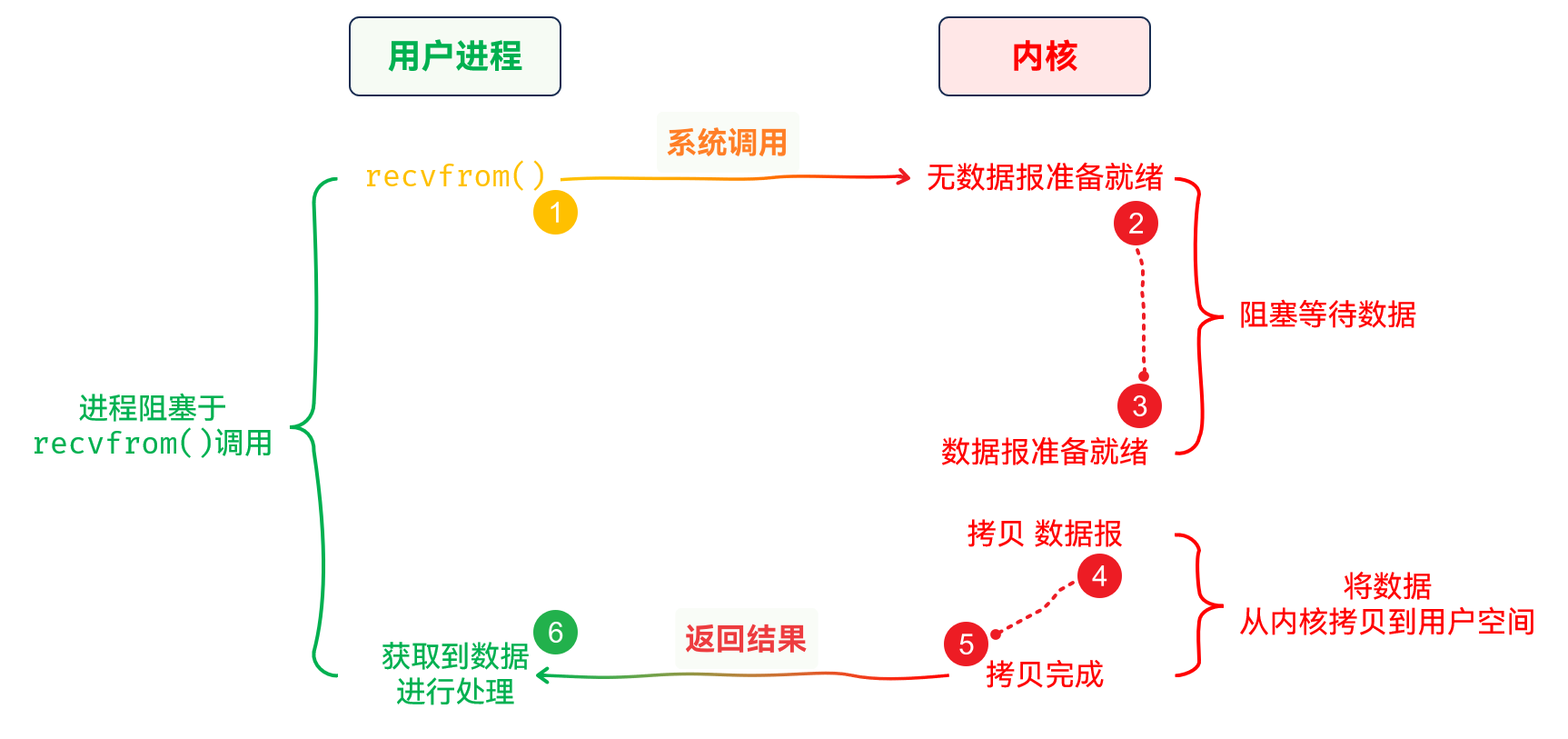
非阻塞IO
IO稍微复杂一些IO, 会等待数据准备就绪 并拷贝完成之后, 再进行返回. 非阻塞IO不会如此IO, 如果内核还未准备好数据, 系统调用不会阻塞等待, 而是会直接返回EWOULDBLOCK或EAGAIN错误码, 此时系统调用结束, 执行流可继续执行其他代码IO, 多了一个询问动作, 而不是呆呆地在内核中等待数据IO操作, 如果数据未准备好, 系统调用就直接返回了IO操作, 往往需要反复执行尝试从文件描述符中拷贝数据, 即 轮询操作, 这其实是一种对CPU资源的浪费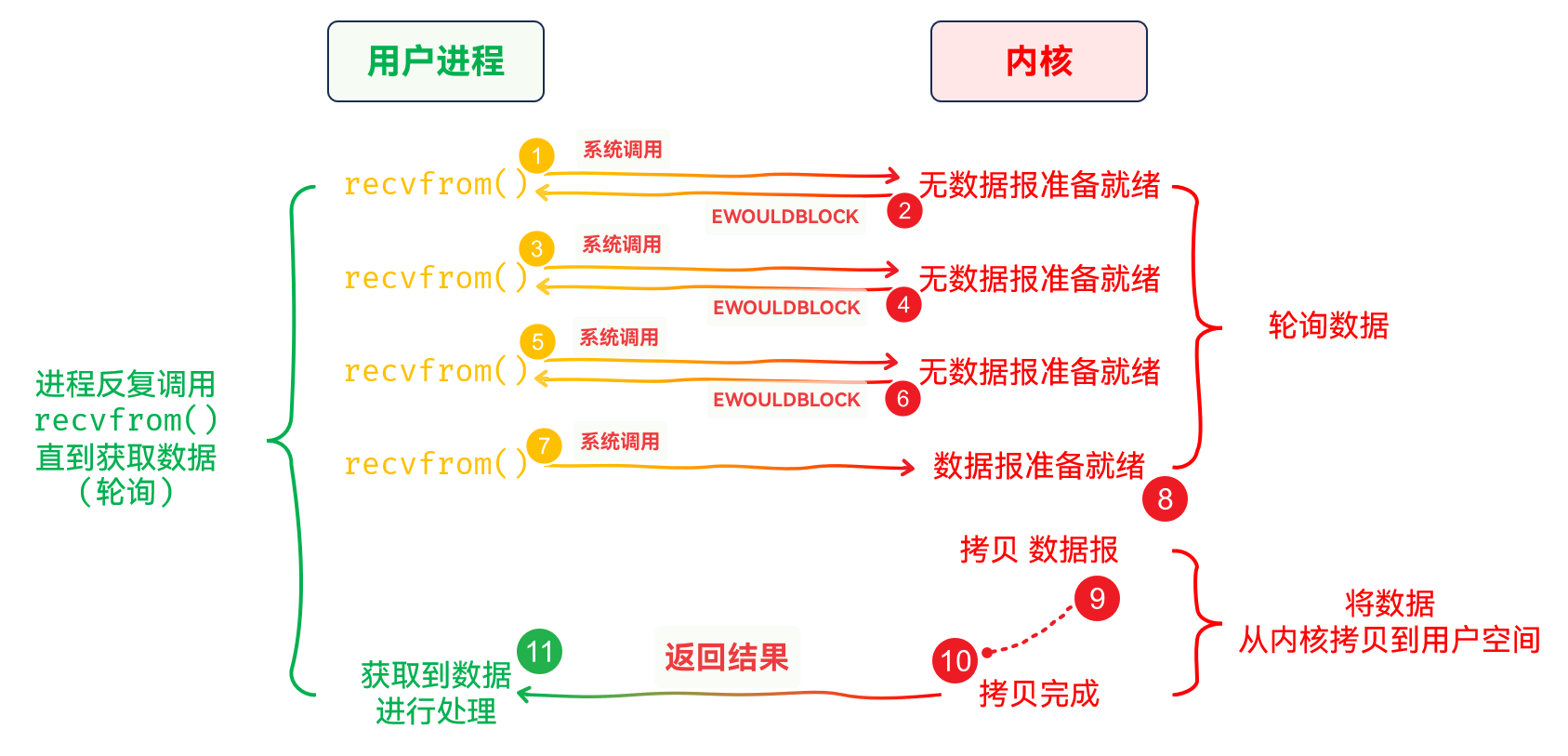
阻塞
IO不会浪费CPU资源, 因为阻塞时执行流不占用CPU资源
信号驱动IO
IO, 从字面上就能猜出个大概Linux进程信号的产生与进程的运行是异步的, 即 进程接收到信号之前, 信号的产生和发送不由进程控制Linux存在一个SIGIO信号, 当文件描述符为信号驱动IO, 当数据准备就绪时, 操作系统就会给进程发送SIGIO信号SIGIO信号, 并在此信号处理函数中进行数据拷贝, 就能实现信号驱动IOIO, 不主动调用 系统调用, 而是捕捉SIGIO信号, 并在SIGIO信号处理函数中调用 系统调用, 实现IO由信号驱动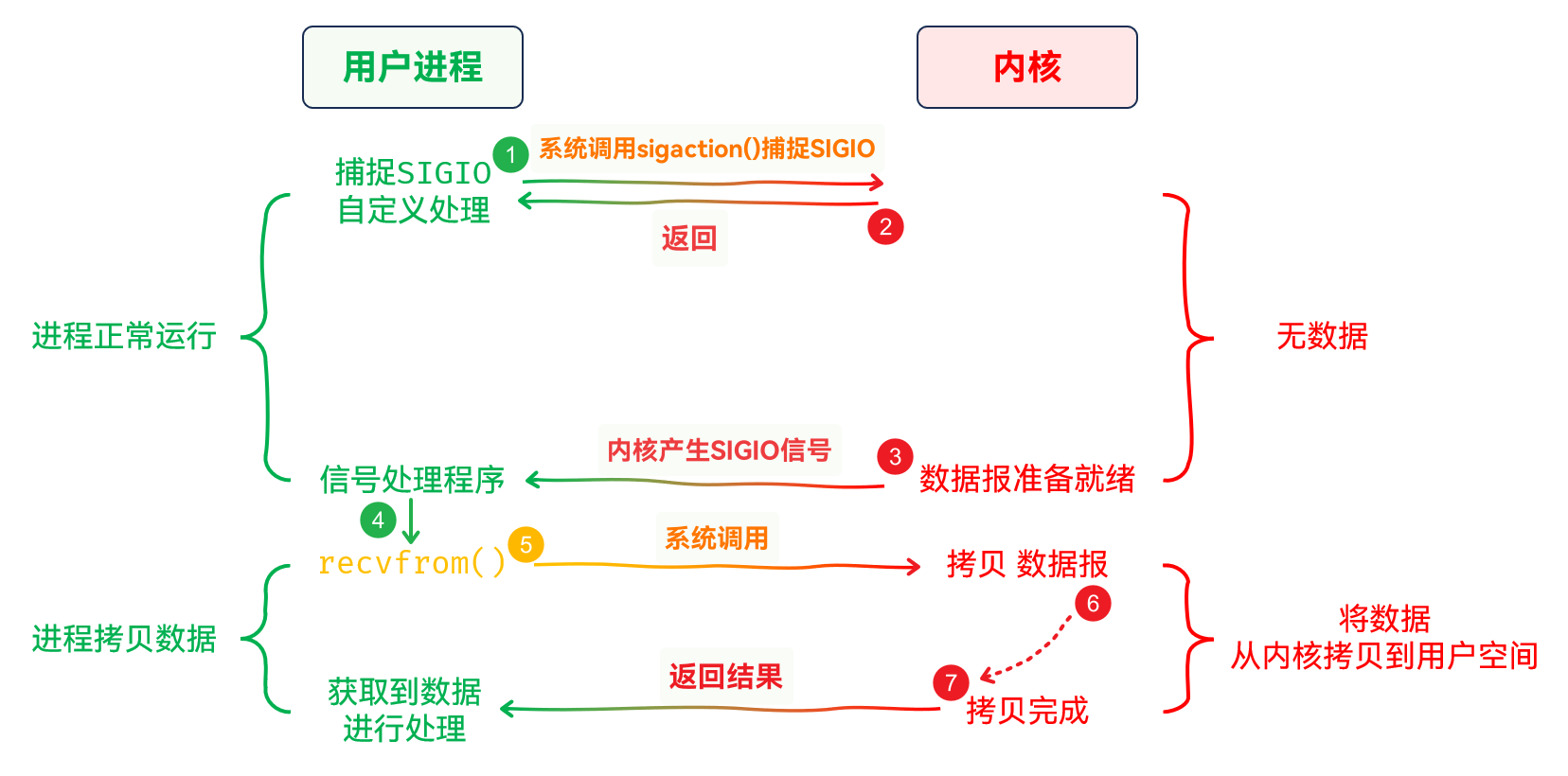
多路转接IO **
IO操作实际上是由等待资源 + 拷贝资源组成之后IO模型的名字上, 可能可以猜到一些苗头TCP网络通信时, 使用recv()可以等待并接收某个套接字的数据, 因为文件描述符默认是阻塞的, 如果想要管理多个连接, 可以使用多线程来处理多个连接的套接字; 或者对不同的套接字设置非阻塞, 进行轮询, 只是浪费CPU资源IO操作; 当某些文件描述符资源就绪, 就对这些文件描述符进行IO操作select()系统调用为例: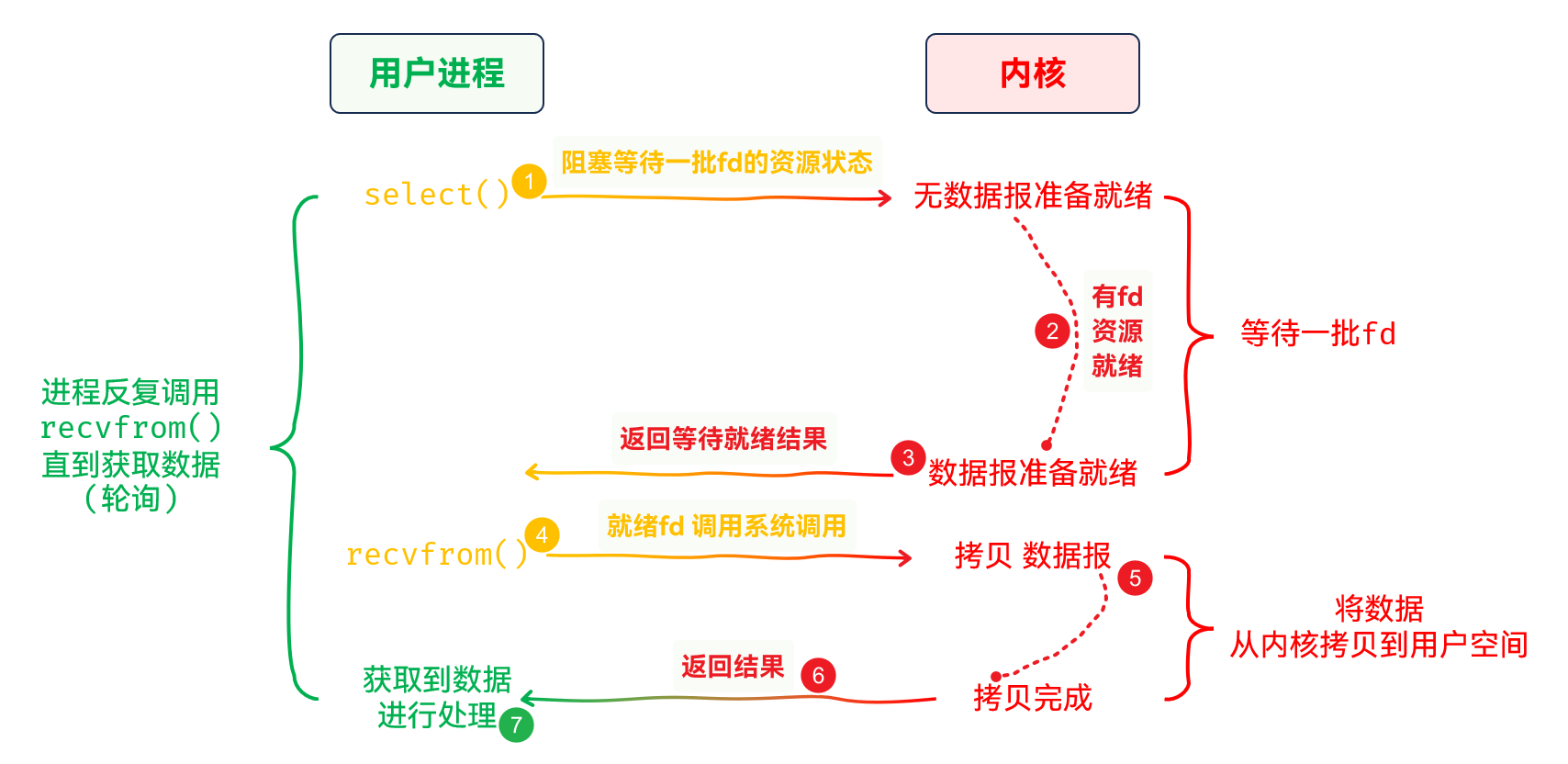
IO操作, 只能等待一个文件描述符, 而多路复用, 能够实现同时对多个文件描述符的等待异步IO
IO也是结合进程信号实现的IO, 是在文件描述符数据就绪之后, 给进程发送SIGIO信号, 让进程执行系统调用拷贝数据IO, 是在设置好异步IO请求之后, 进程就可以放手了, 直到内核完成数据拷贝, 数据已经拷贝到用户空间之后, 内核会给进程发送信号, 再通过自定义信号处理函数, 进行数据处理IO请求时设置好的IO, 需要对指定文件描述符设置异步IO请求(读/写、信号、信号处理、数据存储位置等), 然后等待数据和拷贝数据的工作不由进程执行, 全权交给内核, 内核完成数据拷贝之后会向进程发送信号, 进程处理信号 完成异步IO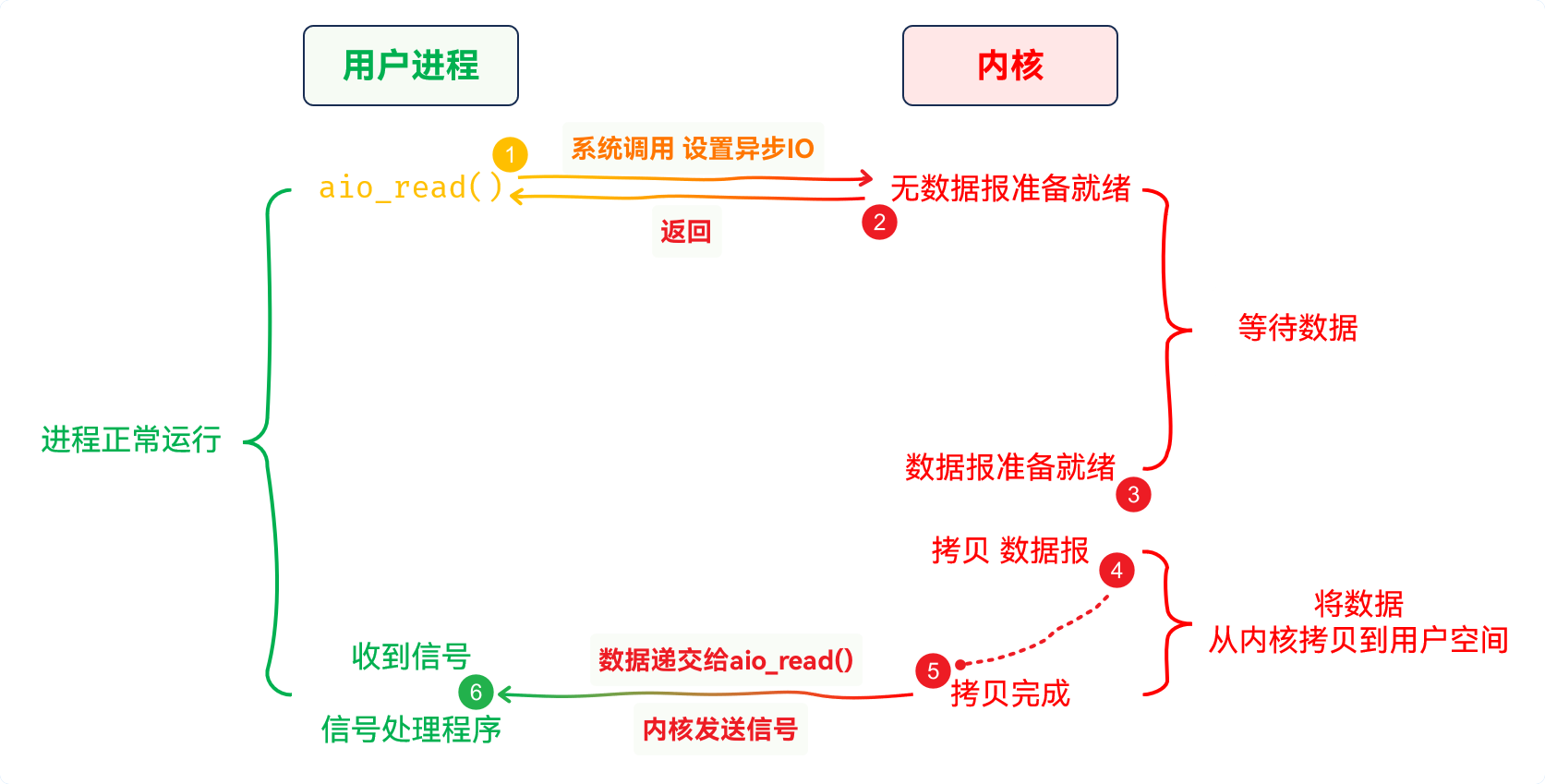
相关名词概念
IO的同步和异步, 是根据系统调用对执行流的影响判断的IO操作的在执行时, 会阻塞执行流的正常运行, 直到IO操作完成, 执行流才会继续运行IO操作的执行, 不会影响原执行流的正常运行, IO操作完成之后, 会通过回调函数或信号的方式通知执行流处理数据这里的同步与异步, 所用场景是
IO操作线程中有同步和互斥, 与这里的并没有关系
线程的同步, 是指一种控制线程以一定顺序执行的策略
线程的互斥, 是指通过锁等手段, 控制线程不能同时运行的策略
简单的非阻塞IO
IO操作, 需要先了解一个系统调用fcntl()int fcntl(int fd, int cmd, ... /* arg */ );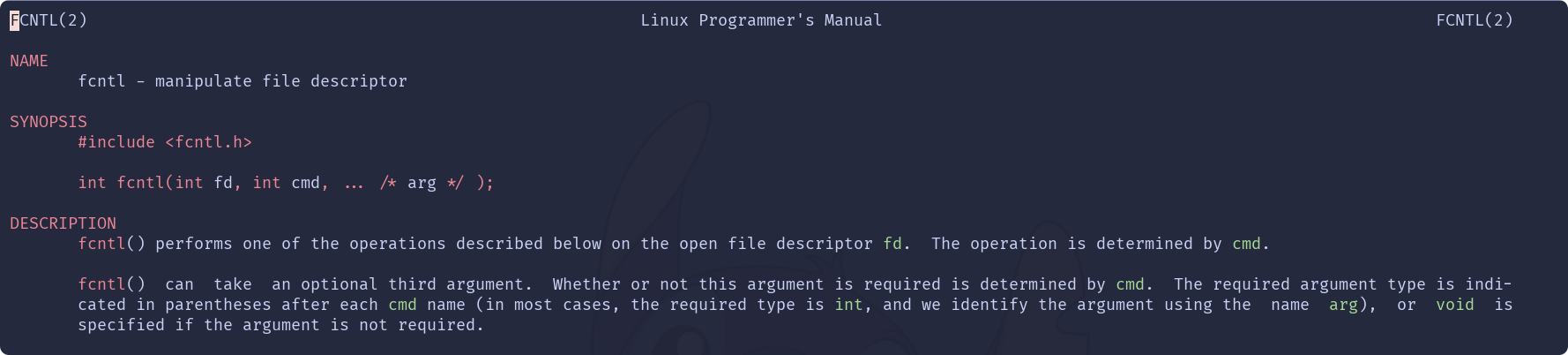
fnctl()系统调用拥有两个显式参数和可变参数, 返回值类型是int:-
int fd很明显, 第一个参数需要传入一个文件描述符
fcntl()就是对此文件描述符进行操作 -
int cmd第二个参数, 需要传入一个命令, 表示要做什么操作
可用的
cmd, 在man手册中都有记录比如, 复制文件描述符相关的、文件描述符相关的、文件描述符状态相关的等等
-
可变参数
可变参数是否需要传参, 都要根据
cmd的传参来决定如果
cmd传入的是F_GETFL, 用来获取文件描述符状态, 可变参数部分就不需要传参如果
cmd传入的是F_SETFL, 用来设置文件描述符的状态, 可变参数部分就需要传参 -
返回值
fcntl()的返回值同样与传入的cmd有关如果
cmd传入F_GETFL, 那么 正确的返回结果就是 表示文件描述符状态的一个数据如果
cmd传入F_SETFL, 那么 正确的返回结果就是0如果发生了错误, 就会返回
-1
只有需要获取文件描述符的某些属性时,
fcntl()的返回值才会有实际的意义, 具体可查看man手册
IO:util.hpp:#ifndef __UTIL_HPP__
#define __UTIL_HPP__
#include <fcntl.h>
#include <unistd.h>
#include <iostream>
namespace Util {
// 对文件描述符设置非阻塞 的函数
bool setNoBlock(int fd) {
// 获取文件描述符的 原有属性
int flag = fcntl(fd, F_GETFL);
if (flag == -1) {
return false;
}
// 设置文件描述符属性
fcntl(fd, F_SETFL, flag | O_NONBLOCK);
return true;
}
} // namespace Util
#endifmain.cc:#include <unistd.h>
#include <cstdio>
#include <cstring>
#include <functional>
#include <iostream>
#include <string>
#include <vector>
#include "util.hpp"
using func_t = std::function<void()>;
int main() {
std::vector<func_t> funcs;
funcs.push_back([]() {
std::cout << "other task1 is running" << std::endl;
});
funcs.push_back([]() {
std::cout << "other task2 is running" << std::endl;
});
funcs.push_back([]() {
std::cout << "other task3 is running" << std::endl;
});
Util::setNoBlock(0);
char buffer[1024] = { 0 };
while (true) {
int n = scanf("%s", buffer);
if (n == -1) {
std::cout << "errno: " << errno << ", desc: " << std::strerror(errno) << std::endl;
for (const auto &f : funcs)
f();
}
else
std::cout << "some data: " << buffer << std::endl;
sleep(1);
}
return 0;
}util.hpp中实现了一个**setNoBlock(int fd)函数, 用来将文件描述符设置为非阻塞模式**-
先调用
fcntl()系统调用,cmd传入F_GETFL, 并接收返回值flag用以获取文件描述符当前的状态属性
获取的状态属性, 与文件描述符的读写状态和访问模式等相关
-
再次调用
fcntl()系统调用,cmd传入F_SETFL, 需要传入可变参数flag | O_NONBLOCK设置文件描述符为非阻塞模式
为什么可变参数要传入
flag | O_NONBLOCK?可变参数部分是需要设置的文件描述符属性, 并且设置是覆盖性的
所以需要在不改变其他属性的前提下, 增加非阻塞模式, 就需要用原有属性 | 新增模式
main.cc中实现了简单的非阻塞IOC/C++中存在一个最常见的阻塞IO文件描述符, 标准输入(fd=0)setNoBlock(0)可以将标准输入设置为非阻塞模式scanf()尝试从键盘获取字符串, 如果没有获取到 就执行其他任务scanf()在不输入数据的情况下, 会导致进程阻塞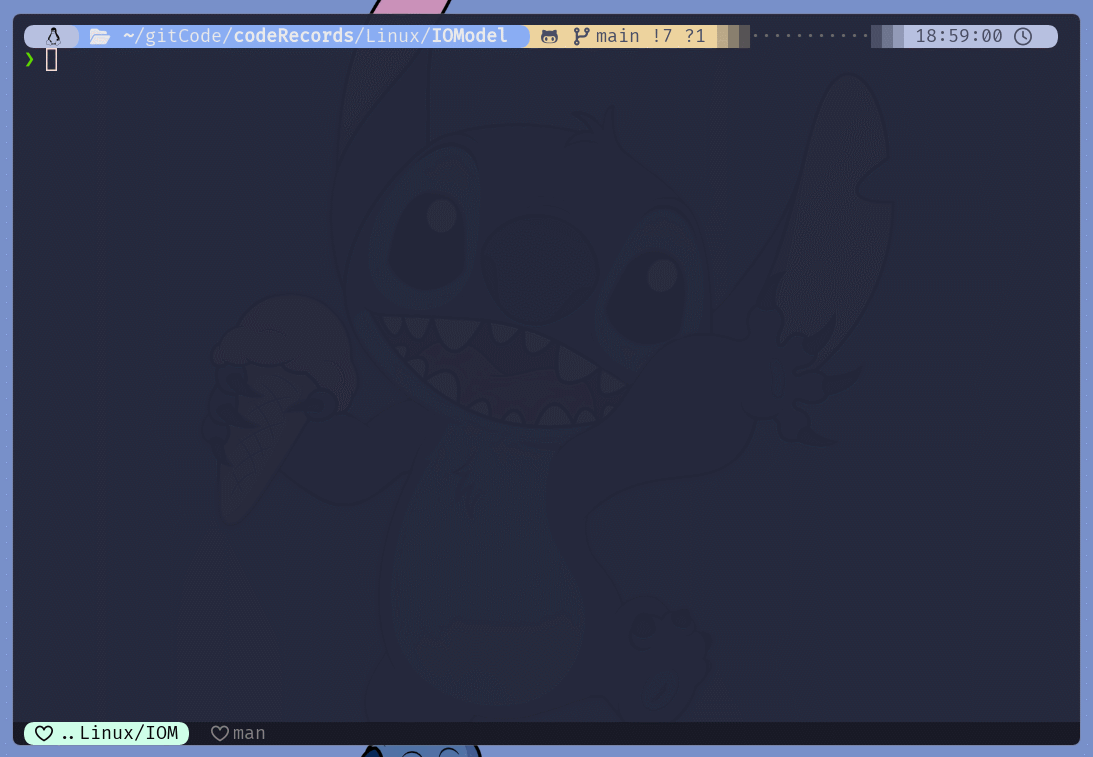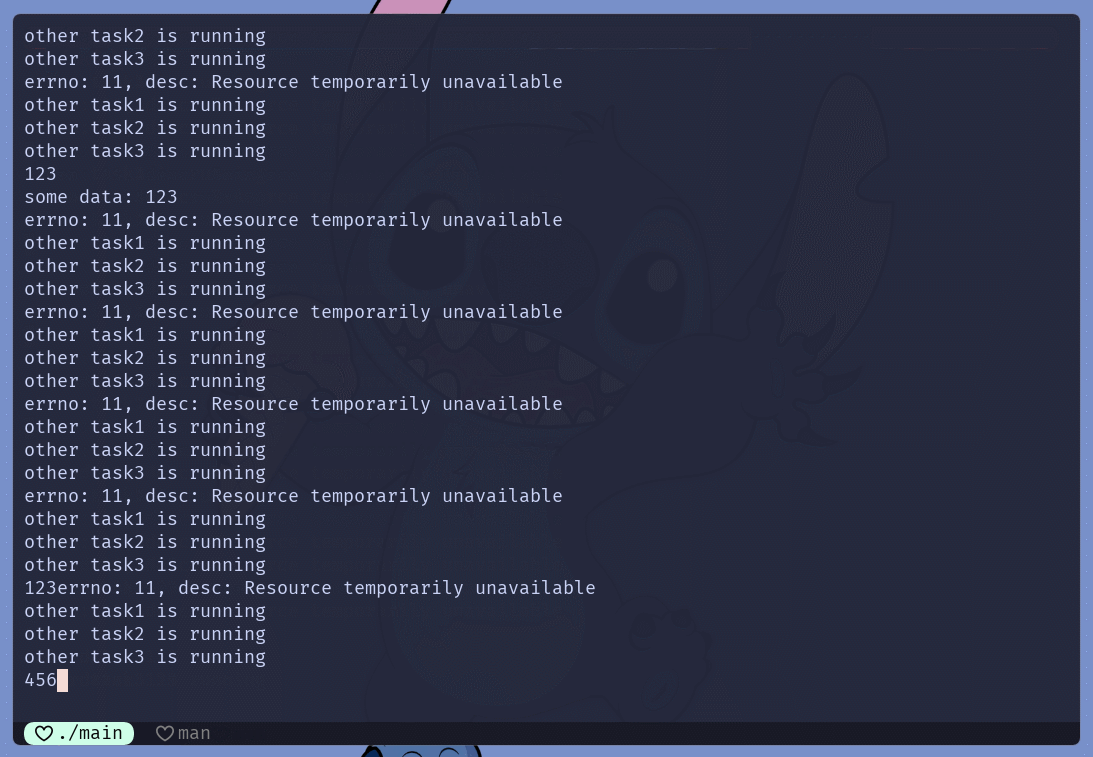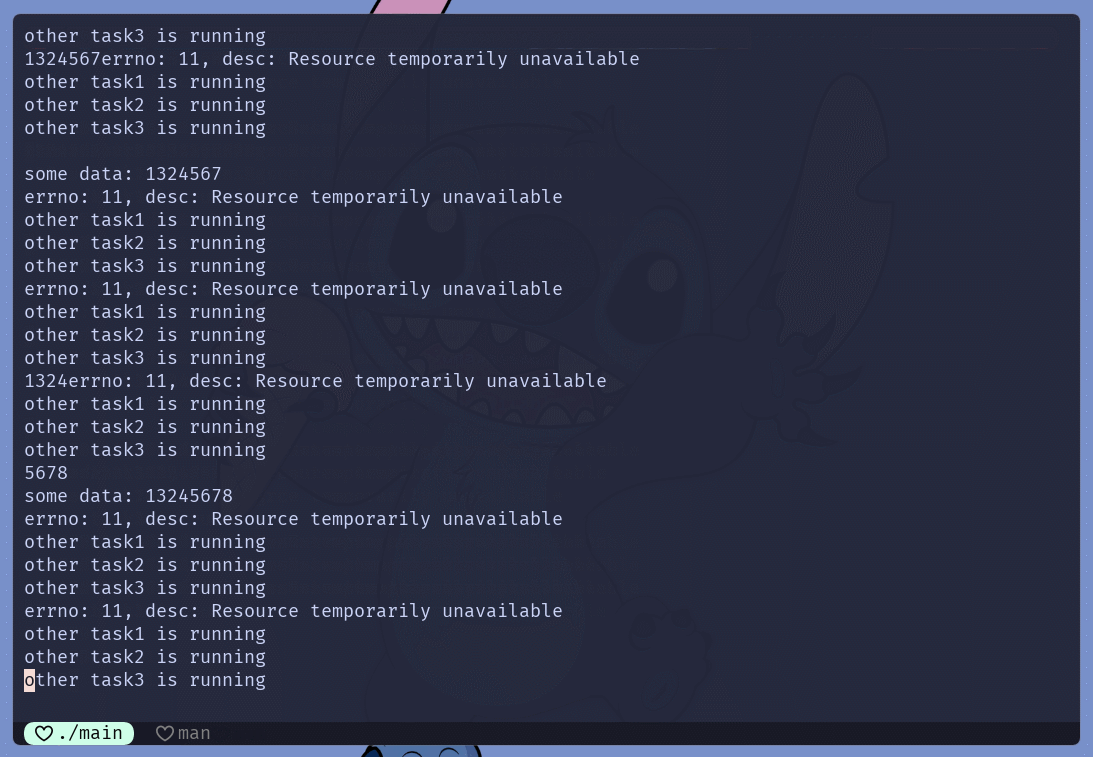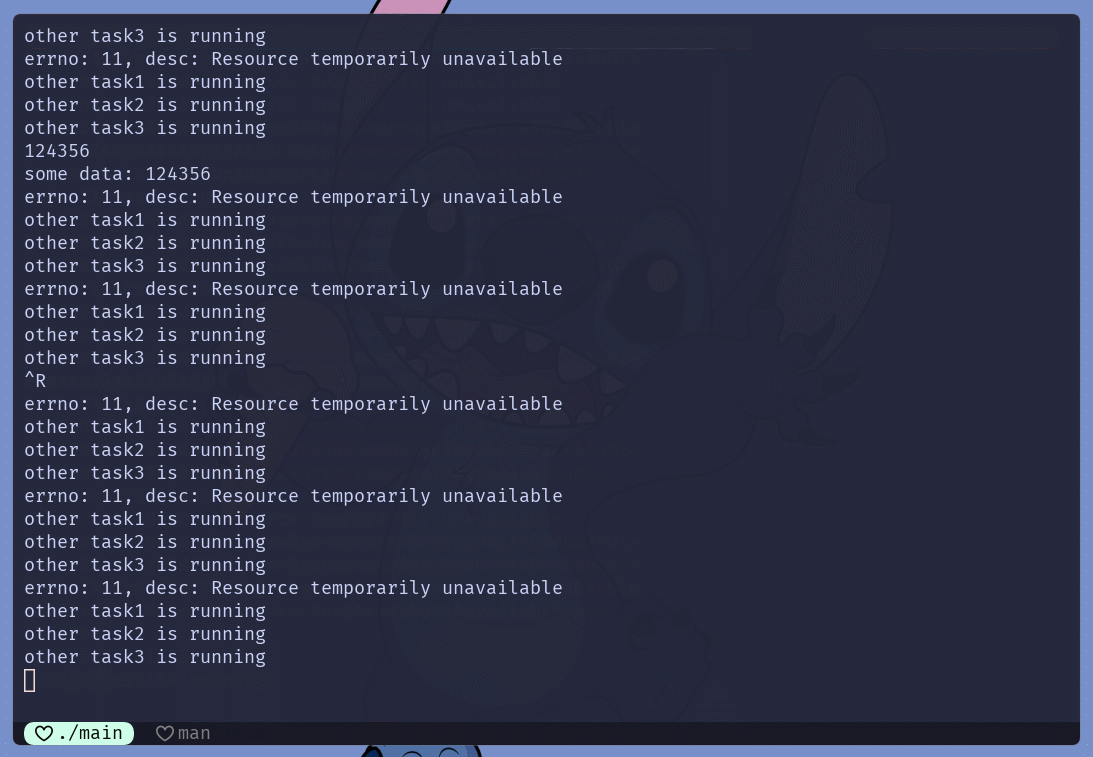
scanf()的返回值是-1, 因为一直在打印错误码funcs中存储的任务IO, 能够很好的体现出非阻塞IO的特点fcntl()系统调用直接设置文件描述符的状态属性之外, 且除read()或write()之外的其他IO系统调用sendto() send() recv() recvfrom()int flag, 也可以通过此参数设置本次IO的属性, 不会影响文件描述符本身的属性多路转接IO模型实现 **
Linux提供了三个不同的实现多路转接的接口select()、poll()和epoll()epoll()可以看作是其中最优秀的select()
Linux中select()的函数原型是这样的:int select(int nfds,
fd_set *restrict readfds,
fd_set *restrict writefds,
fd_set *restrict exceptfds,
struct timeval *restrict timeout);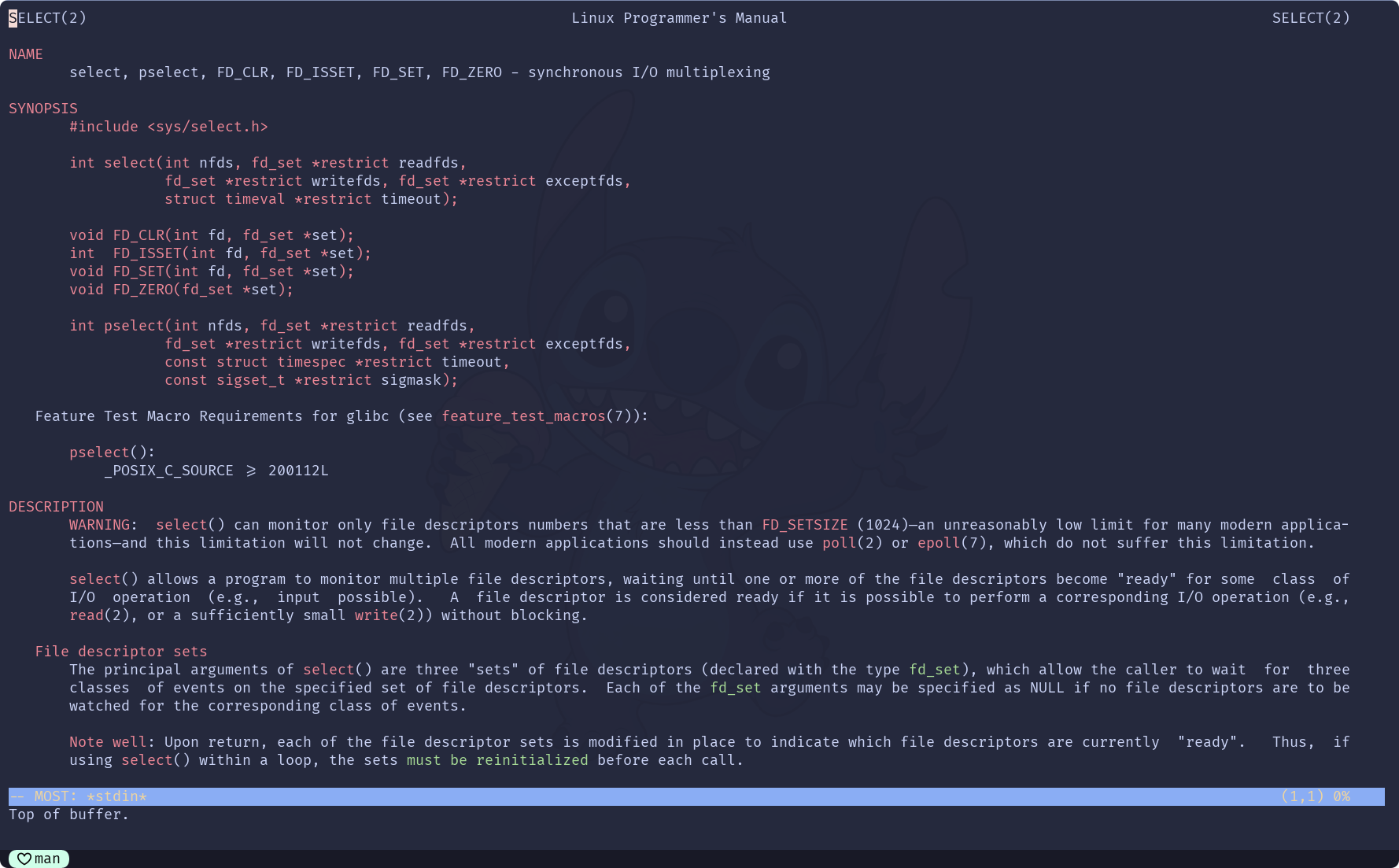
select()存在4个参数:-
int nfds第一个参数, 需要传入所监视文件描述符中的最大值+1
比如, 如果要监视的文件描述符有
3459, 那么此参数就应该填入9+1不是传入监视的文件描述符的个数, 而是所监视文件描述符中的最大值+1
-
fd_set *restrict readfds第二个参数, 需要传入需要监视可读状态的文件描述符集
即, 要监视是否能从文件描述符中读取数据
-
fd_set *restrict writefds第三个参数, 需要传入需要监视可写状态的文件描述符集
即, 要监视是否能向文件描述符中写入数据
-
fd_set *restrict exceptfds第四个参数, 需要传入需要监视异常状态的文件描述符集
即, 要监视文件描述符是否发生异常
什么是异常状态呢?
比如, 存在外带数据, 异常关闭, 读取发生错误等
-
struct timeval *restrict timeout第五个参数, 需要传入**
select()本次监视的最长阻塞时间**这个参数是用来控制
select()单次的等待时间的, 如果在此时间内没有文件描述符就绪select()将会返回0
select()的参数中存在两个结构体类型, 可能比较陌生:-
struct timeval![]()
这个结构体比较简单, 只有两个成员
time_t tv_sec, 实际是long int类型的, 用于表示秒suseconds_t tv_usec, 实际也是long int类型的, 用于表示微秒 -
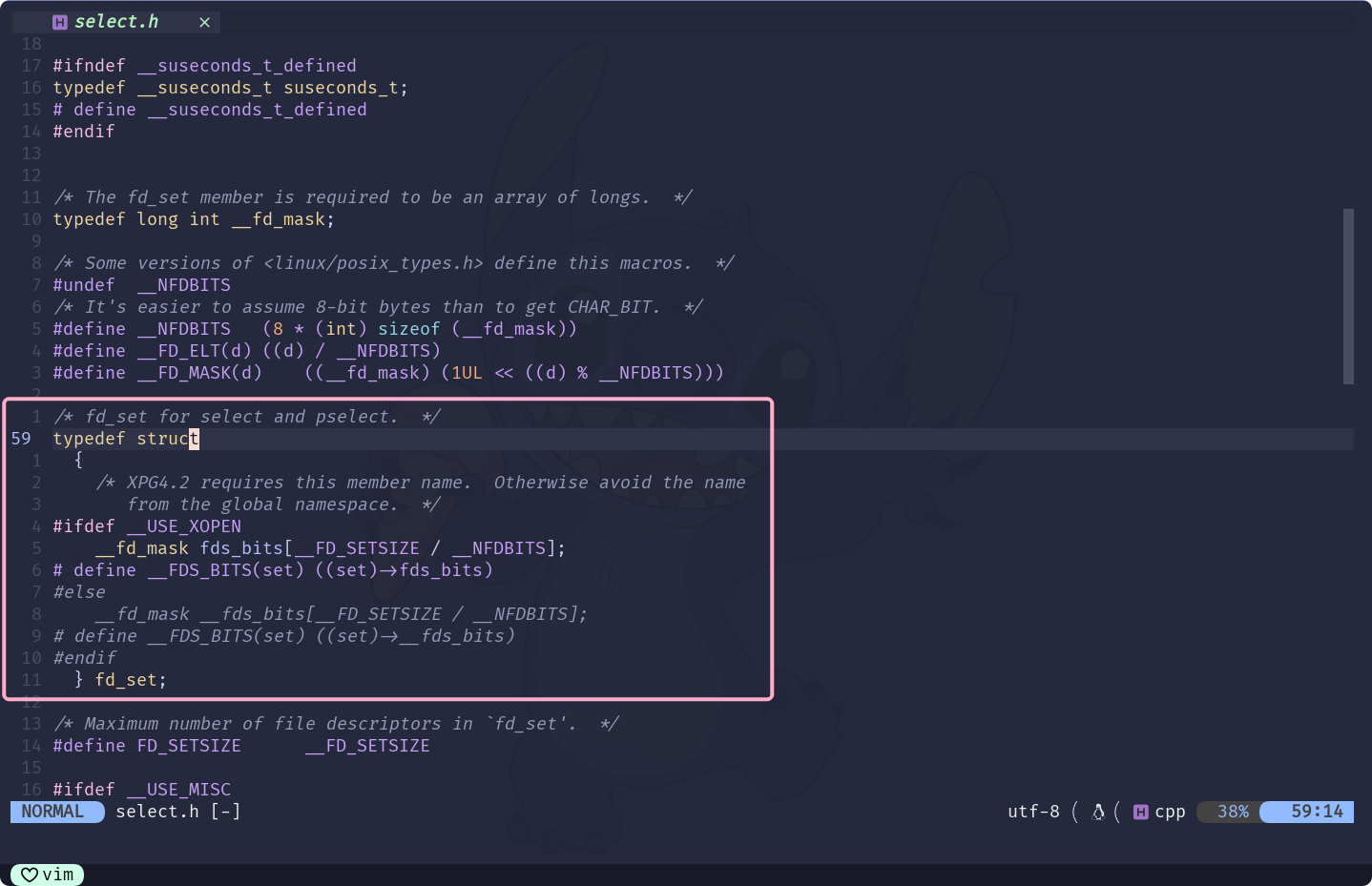
fd_setfd_set是一个位图结构, 表示文件描述符集![]()
struct fd_set存在一个成员变量__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS]也就是一个数组,
__fd_mask实际就是long int类型__FD_SETSIZE在Linux中是1024的宏定义而
__NFDBITS则是(8 * (int)sizeof(__fd_mask))所以,
struct fd_set中其实只是存在一个long int fds_bits[]数组, 数组长度为1024 / (8 * 8) => 1024 / 64 => 16即,
fd_set底层是long int fds_bits[16],long int大小为8字节数组长度为16所以,
fd_set底层是一个最长1024位的位图

select()的接口, 再了解一下select()的使用过程select()中间三个fd_set类型的参数, 是以位图的形式传入需要监视的文件描述符select()第一个参数传入需要被监视的文件描述符中的最大值+1, 因为select()是通过遍历位图实现对设置的文件描述符进行监视的poll()
epoll()
作者: 哈米d1ch 发表日期:2024 年 12 月 3 日