
C语言
2024 年 11 月 21 日
[C/CPP] memcpy()的一个使用问题
使用memcpy()将字符数组的前几个元素, 拷贝到一个整型变量中时, 发现了一个问题...
C语言中,
memcpy()可以用来按字节大小将数据拷贝到另外一个变量中, 不过一般情况下都是在相同类型之间拷贝不过, 今天使用的时候, 需要将长度为4的
unsigned char数组 整合至一个unsigned int变量时, 发现执行结果与预想的结果不一致, 于是就去研究了一下下面这段代码的执行结果, 可以目测一下是什么:
#include <stdio.h>
#include <string.h>
int main() {
unsigned char array[4] = {0x12, 0x34, 0x56, 0x78};
unsigned int num = 0;
memcpy(&num, array, 4);
printf("0x%X\n", num);
return 0;
}执行结果如下:
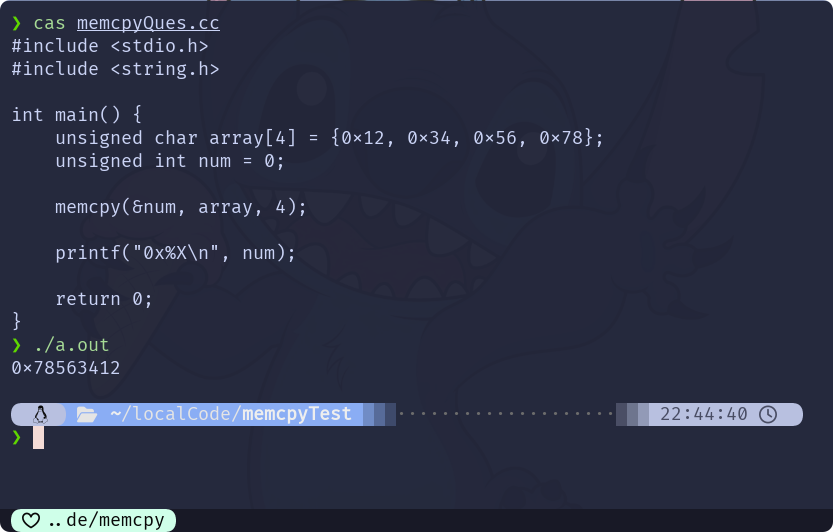
虽然之前简单地模拟实现过
memcpu()函数, 但是第一次看见类似这样的结果时, 愣了一下反应过来可能是字节序的问题, 又一想
unsigned char类型本身只有1字节, 并且数组之间元素相互独立, 所以 应该是不受字节序影响的而且, 如果 字符数组之间通过
memcpy()进行拷贝, 也不会出现预期不一致的情况: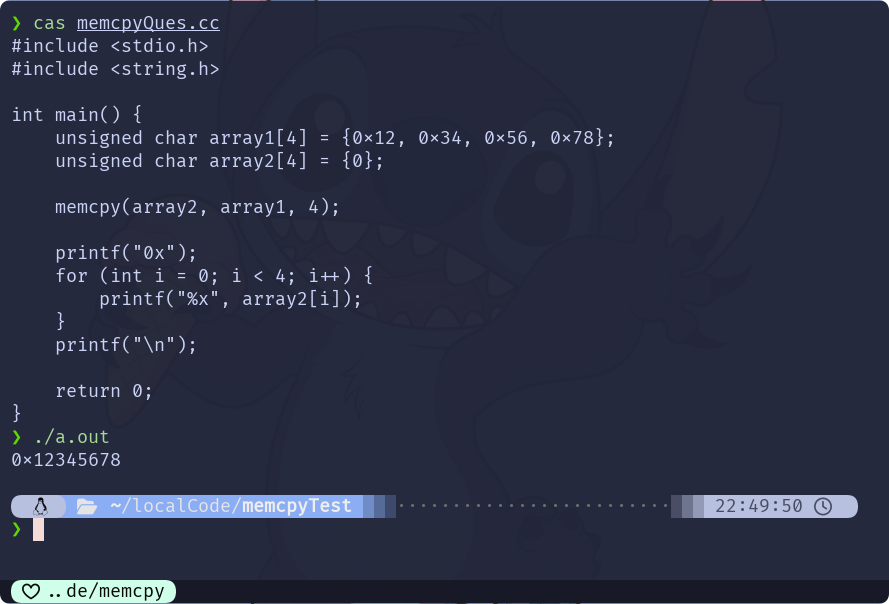
所以, 应该不仅仅是字节序的问题, 应该还有
unsigned char与unsigned int之间的问题然后, 就思考了一下
memcpy()的执行过程memcpy()是以字节为单位, 将数据 从低地址到高地址 逐字节从一个变量中拷贝到另一个变量中 的在上例中的
unsigned char数组中, 从低地址到高地址就是 array+0->array+3, 对应元素array[0]->array[3]而
unsigned int是4字节大小的一个类型, 1个变量就占4个字节, 这样的数据在内存中的存储方式是收到 大小端字节序 影响的无论大小端字节序, 都是以字节为单位的影响的, 所以只对大小>1字节的数据有影响
小端字节序
一个变量所占的内存地址中, 低地址处 用于存储变量的低位字节, 高地址处 用于存储变量的高位字节
举个例子:
若 存在
int num = 0x12345678(1是高位, 8是低位)则, 此变量在内存中占用4字节的空间, 以字节为单位, 假设首地址为
0x0000, 那么末地址该是0x0003那么, 若使用小端字节序存储数据, 从低地址 到 高地址, 存储的数据该为:
地址 存储数据 0x00000x780x00010x560x00020x340x00030x12因为 低地址 存储 低位字节, 高地址 存储 高位字节
大端字节序
大端字节序的存储方式, 与小端字节序相反
在大端字节序中, 一个变量所占的内存地址, 低地址处 用于存储变量的高位字节, 高地址处 用于存储变量的低位字节
以相同的数据 举个例子:
若 存在
int num = 0x12345678(1是高位, 8是低位)则, 此变量在内存中占用4字节的空间, 以字节为单位, 假设首地址为
0x0000, 那么末地址该是0x0003那么, 使用大端字节序存储数据, 从低地址 到 高地址, 存储的数据该为:
地址 存储数据 0x00000x120x00010x340x00020x560x00030x78
以人的视角来看, 其实 大端字节序更符合视觉逻辑
数据是什么, 就用怎样的顺序进行存储
比如
0x12345678, 12在左边, 就先用低地址的空间进行存储, 78在右边, 就最后用高地址的空间进行存储但, 在计算机领域, 还是小端字节序更加常见一些
对
unsigned int这样会被字节序影响存储方式的数据类型来说, 关注环境的大小端字节序使用是很重要的计算机中通常使用小端字节序进行数据存储, 那么对于
unsigned int类型来说低位字节的数据, 就要存储在低地址, 高位字节的数据, 就要存储在高地址
而对于
memcpy()来说, 它是从低地址到高地址 逐字节进行数据拷贝的, 对它来说传入的数据只需要按照字节序进行拷贝就可以了所以, 如果使用
memcpy()将长度为4的unsigned char array[4]数组数据拷贝到一个unsigned int num变量中那么,
array[0]就是低地址的数据, 该被存储在num的低地址, 也就是最右边, 最低位字节以此从
array[0]到array[3], 从低地址到高地址, 存储在num的低地址到高地址, 实际也就是 最低位字节到最高位字节最终, 整个拷贝过程完成, 就实现了
array[4] = {0x12, 0x34, 0x56, 0x78}拷贝到num结果为0x78563412如果, 某个平台使用的是大端字节序存储数据, 相信应该不会出现上面的这个现象
OK, 这是今天在使用
memcpy()时遇到的一个小问题文章结束, 感谢阅读~
版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
作者: 哈米d1ch 发表日期:2024 年 11 月 21 日