
[C++] C++11新特性--右值引用的深入分析: 右值引用、万能引用、引用折叠、完美转发、移动语义...
右值引用
左值 与 左值引用
&这个符号, 在C语言中表示取地址&引用在C++11之后 完整的叫法是左值引用=的左边, 是一个表示数据的表达式, 比如: 变量名、解引用的指针等, 可以对它取地址, 也可以给它赋值, 它在内存中有一块持久维护的地址空间, 不是临时的const修饰的左值, 不能给它赋值, 但是可以取它的地址int a = 10;
int* b = &a;
int c = *b;
const int d = *b;
int &e = a;
int &f = d;a、b、c、d都是左值, 都可以对其取地址int &e和int &f都为左值引用const引用就可以引用右值:#include <iostream>
int main() {
// 这个是编译不通过的
//int &g = 10;
// 这个是可以编译通过的
const int &g = 10;
return 0;
}-
int &g = 10;无法编译通过![]()
-
const int &g = 10;可以编译通过![]()


明确理解对象的 类型和“值型” ***
int a = 10;
int& b = a;a的类型是什么? a本身是一个什么值?b的类型是什么? b本身是一个什么值?a的类型是int, a本身是一个左值b的类型是int&, b本身是一个左值右值 与 右值引用
C++11之后, 出现了另一种引用: 右值引用=的右边, 也是一个表示数据的表达式, 但它通常是一个常量或临时数据: 字面常量、表达式返回值、函数返回值等等, 这些表达式 无法对它取地址, 也无法给它赋值 的, 即 无法被修改int x = 1, y = 2;
1;
2;
x + y;
min(x, y);
int&& rr1 = 1;
int&& rr2 = x + y;
int&& rr3 = fmin(x, y);1、2、x + y、min(x, y) 都是右值, 无法对其取地址, 也无法给其赋值int&& rr1、int&& rr2和int&& rr3, 则都是右值引用对象, 右值引用的符号是&&#include <iostream>
int main() {
int m = 1;
int&& n = m;
return 0;
}
&10int&& n = 1; 则n被看作一个左值, 可以给n赋值!- 可以取地址的, 有名字的, 非临时的就是左值
- 不能取地址的, 没有名字的, 临时的就是右值
移动语义 **
代码中的深拷贝
July::string部分代码(下面称呼以string代替):
int转string的to_string()函数string对象, 拷贝构造string对象、给string对象赋值时, 会自动的调用拷贝构造函数和赋值重载函数string的数据进行深拷贝int类型转换为string类型的to_string()函数string类型的, 是不能使用左值引用的, 因为返回数据是一个临时对象string的例子, 如果是更复杂的类, 深拷贝消耗的资源可能是非常巨大的左值引用做返回值节省资源的例子:
string的+=重载实现时, 要实现连续+=就要将+=之后的string作为返回值返回如果直接传值返回, 还是会造成深拷贝
所以, 可以使用左值引用返回
右值引用优化深拷贝
-
新的临时对象返回方式
这里的新的返回方式并不是指编写方式发生了改变, 即 返回值类型不做变化的, 依旧是传值返回
而是指,
C++11之后 当一个函数返回的数据是一个临时对象 或 直接返回一个右值时(出了函数就要销毁的数据做返回值), 编译器会将返回值类型 识别为右值引用类型 -
两个新的 类的默认成员函数
-
移动构造函数
什么是移动构造函数?
以
string为例, 要实现移动拷贝构造, 它的函数名是这样的:string(string &&str) : _str(nullptr) , _size(0) , _capacity(0) { ... }并且, 移动拷贝构造函数体的实现方法, 通常是直接将传入的参数拥有的数据 与 对象的成员数据进行交换
那么,
string之中, 实现应该是这样的:void swap(string& str) { std::swap(_str, str._str); std::swap(_size, str._size); std::swap(_capacity, str._capacity); } string(string &&str) : _str(nullptr) , _size(0) , _capacity(0) { swap(str); }这样传入右值引用参数, 并直接交换传参数据和对象成员数据来实例化对象的函数
就叫移动构造函数
-
移动赋值重载函数
根据移动构造函数的实现, 可以很快的推断出 移动赋值重载函数的实现:
void swap(string& str) { std::swap(_str, str._str); std::swap(_size, str._size); std::swap(_capacity, str._capacity); } string& operator=(string &&str) { swap(str); return *this; }这样传入右值引用参数, 并直接交换传参数据 和对象成员数据来给对象赋值的函数
就叫移动赋值重载函数
这两个默认成员函数, 在完成对象实例化或对象赋值时, 没有发生数据拷贝
-
C++11之后, 类添加了这两个默认成员函数之后, 可以解决很大一部分的深拷贝问题C++11之后, 当一个函数的返回值类型为传值返回, 且返回的是一个函数内的临时变量或其他类型的右值时编译器优化构造函数(移动语义后)
C++11引入了右值引用, 引入了移动构造之后, 编译器又会做什么优化呢?to_string()为例:July::string to_string(int value) {
bool flag = true;
if (value < 0) {
flag = false;
value = 0 - value;
}
July::string str;
while (value > 0) {
int x = value % 10;
value /= 10;
str += ('0' + x);
}
if (flag == false) {
str += '-';
}
std::reverse(str.begin(), str.end());
return str;
}C++11之前to_string()的返回值, 去实例化新的string对象时- 传值返回, 需要生成临时对象, 会发生一次拷贝构造
- 使用
string对象 实例化string又会发生一次拷贝构造
return时的临时对象做返回值, 去调用拷贝构造实例化新的string对象C++11之后- 传值返回, 需要生成临时对象, 但编译器会识别出右值引用返回, 所以 发生一次移动构造
- 使用 一个右值
string对象实例化string, 又会发生一次移动构造
return时的临时对象做返回值, 去移动构造实例化string对象C++11之后, 所有的STL容器也增加了这两个成员函数:vector: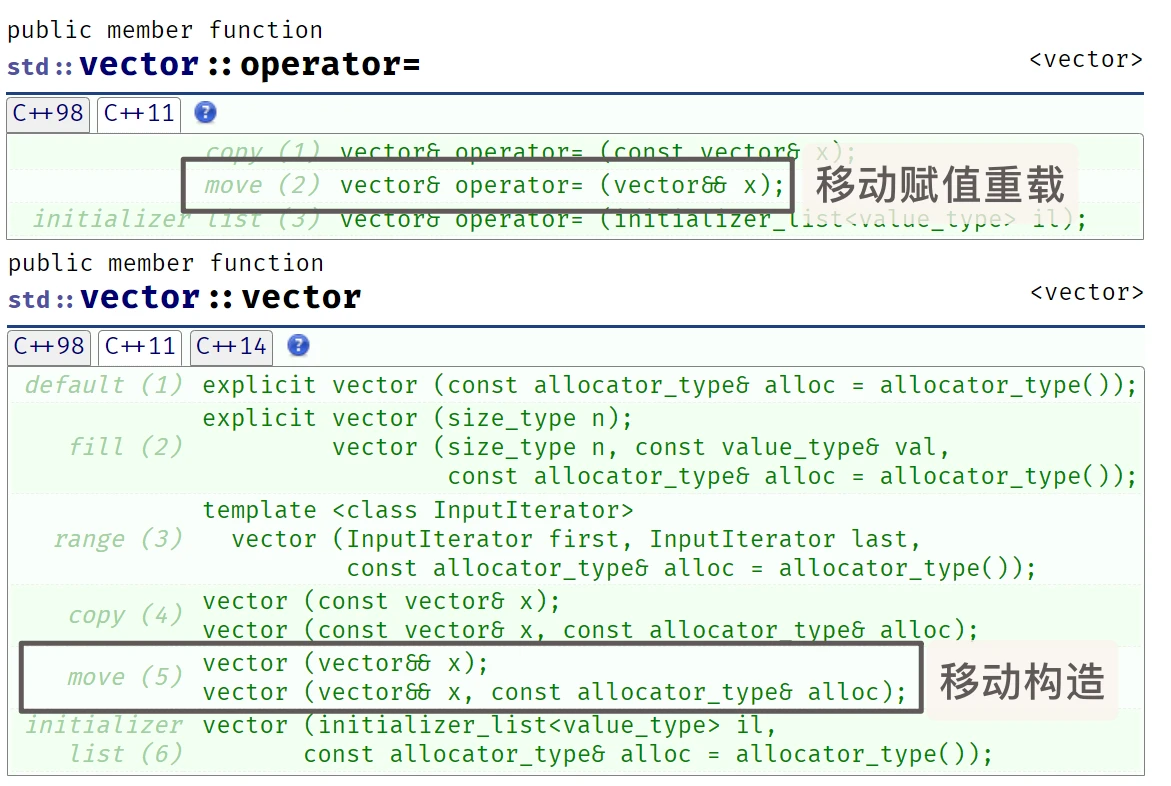
string: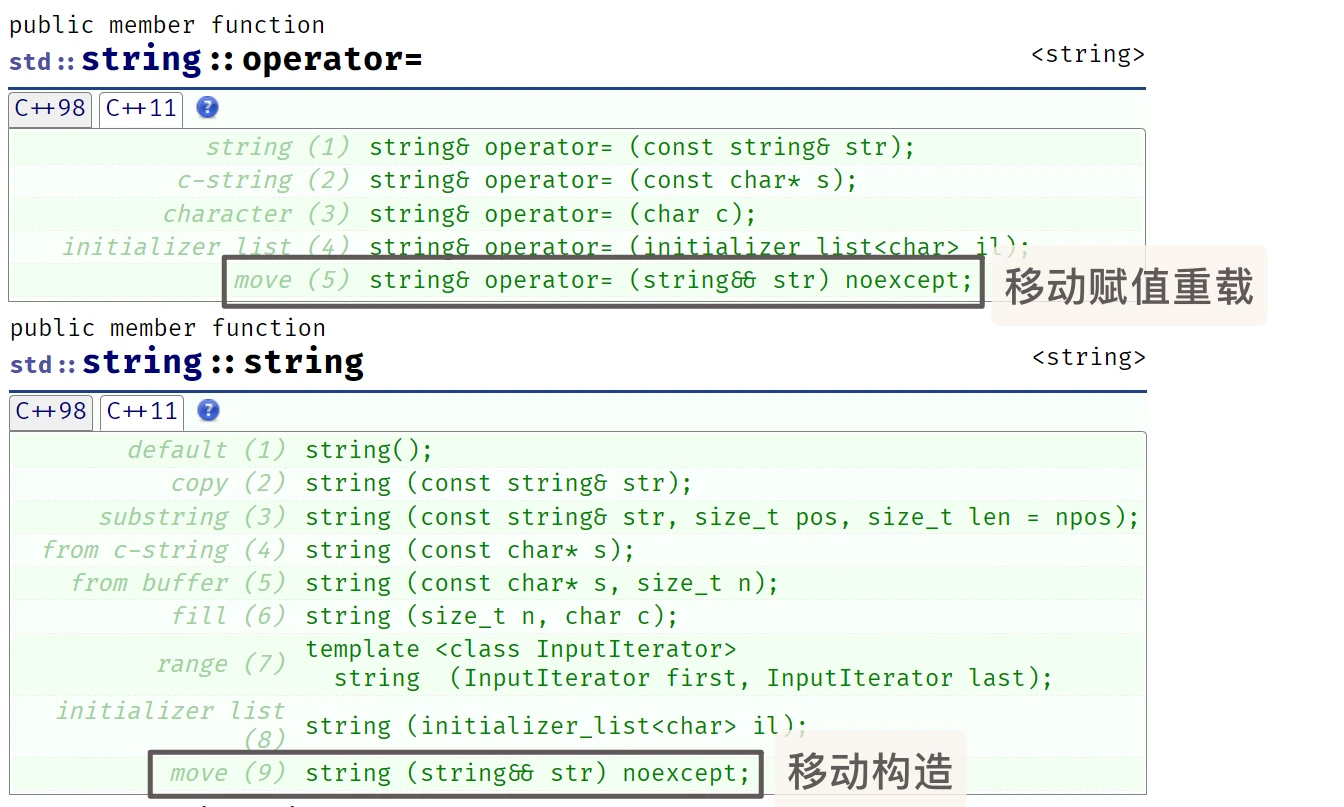
move()
C++11不仅提出了右值引用, 还增添了一个新的函数std::move()
move()将左值对象转换为对象的右值引用返回move(), 返回值是传入对象的右值引用, 一个将亡值move()的使用场景在哪呢?move()实际上是为了更好的支持移动语义objectobject, 实例化新对象 或 给其他对象赋值, 编译器会调用普通拷贝构造或普通赋值重载, object不会失去它的原数据move(object)的返回值, 实例化新对象 或 给其他对象赋值, 因为move(object)的返回值是object的右值引用, 是一个右值, 编译器就会调用移动构造和移动赋值重载, 之后 object的原数据会被置换走, object会拥有另一个对象的原数据move()的使用需要谨慎move()可能会导致左值对象随时失去原数据或被销毁
move()的返回值是传入参数的右值引用但, 如果使用右值引用对象接收
move()的返回值:T object; T&& rRefObject = move(object);此时,
rRefObject并不是一个右值, 因为右值引用对象是一个左值
容器接口中的右值引用
push_back()、insert()等一系列向容器中插入数据的接口:

vector, 其他容器也同样实现了数据添加接口的右值引用参数版本万能引用 **
C++11引入了右值引用, 用 && 表示C++11之后就会有些场景, 就需要使用右值引用类型的参数作为模板参数July::string类为例, 但是执行这段代码:void Fun(int &x) {
cout << "左值引用" << endl;
}
void Fun(const int &x) {
cout << "const 左值引用" << endl;
}
void Fun(int &&x) {
cout << "右值引用" << endl;
}
void Fun(const int &&x) {
cout << "const 右值引用" << endl;
}
template<typename T>
void PerfectForward(T&& t) {
Fun(t);
}
int main() {
PerfectForward(10); // 传右值
int a;
PerfectForward(a); // 传左值
PerfectForward(std::move(a)); // 传右值
const int b = 8;
PerfectForward(b); // 传const左值
PerfectForward(std::move(b)); // 传const右值
return 0;
}Fun(), 参数都是引用类型, 会根据传入的参数类型, 判断const左值或右值&&右值 左值 右值 const 左值 const 右值
&&用在模板中, &&就不再是右值引用了, 而是 万能引用引用折叠 **
template<typename T>
void Func(T&& arg) {}-
存在这样调用
Func()int elem = 10; Func(elem);此时,
Func()推导T为int&类型此时, 会发生引用折叠,
arg的类型会折叠为左值引用折叠规则:
T& &&—>T& -
存在这样调用
Func()int elem = 10; Func(std::move(elem));此时,
Func()推导T为int&&类型此时, 会发生引用折叠,
arg的类型会折叠为右值引用折叠规则:
T&& &&—>T&&
auto推导时发生引用折叠:int&& getRValue() {
return 10;
}
int& retLValue(int& val) {
return value;
}
int main() {
int lval = 20;
int& lref = retLValue(lval);
int&& rref = getRValue();
auto& val1 = rref; // auto& &&
auto& val2 = lref; // auto& &
auto&& val3 = lref; // auto&& &
auto&& val4 = rref; // auto&& &&
return 0;
}val1 val2 val3会被折叠为auto&, 最终为int&val4则会被折叠为auto&&, 最终为int&&T&& &&时, 引用折叠才会折叠为&&右值引用int &&a = 10;
int* b = &a;
a = 7;a, 可以被取地址, 也可以被赋值void fun(int&& f) {}
int main() {
int &&d = 10;
fun(d);
return 0;
}
July::string类// 默认构造
string(const char* str = "")
: _size(strlen(str))
, _capacity(_size) {
// 添加提示语句
cout << "默认构造" << endl;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
string(string&& str) {
// 暂不实现功能
cout << "移动构造" << endl;
}
// 拷贝构造函数 传统
string(const string& s)
: _size(s._size)
, _capacity(s._capacity) {
// 添加提示语句
cout << "拷贝构造" << endl;
_str = new char[_capacity + 1];
strcpy(_str, s._str);
} int main() {
July::string &&str = "12345";
July::string s = str;
return 0;
}
PerfectForward()函数时传入的是右值引用.Fun()函数, 依旧会被识别为左值, 就是因为这两个原因T&& &&折叠之后依旧表示右值引用Fun(t) 调用时, t直接用作表达式, 会被认为是左值完美转发 **
C++11的一个新接口: std::forward()完美转发
void Fun(int &x) {
cout << "左值引用" << endl;
}
void Fun(const int &x) {
cout << "const 左值引用" << endl;
}
void Fun(int &&x) {
cout << "右值引用" << endl;
}
void Fun(const int &&x) {
cout << "const 右值引用" << endl;
}
template<typename T>
void PerfectForward(T&& t) {
cout << "非完美转发: ";
Fun(t);
cout << "完美转发: ";
Fun(std::forward<T>(t));
cout << endl;
}
int main() {
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}
std::forward<type>()的返回值是传入参数的原类型std::forward<type>()是如何做到的?template <typename _Tp>
constexpr _Tp&& forward(typename std::remove_reference<_Tp>::type& __t) noexcept {
return static_cast<_Tp&&>(__t);
}std::forward<type>()的参数:-
会先被
std::remove_reference()消除传入的模板参数类型的 引用状态即, 将传入类型还原为无引用的原始状态:
int&&->intint&->int -
然后,
&保证数据, 会以原始类型的左值引用, 作为形参进入forward()这里
&防止数据传值传参, 形参变为临时数据 -
将数据的类型, 从原始类型的左值引用(形参类型), 强制转换为传入模板参数类型的
&&, 并返回
std::forward<type>()做的, 就是将传入数据的类型加上了&&并返回type是T& 就变为T& &&, 并返回, 发生引用折叠T&type是T&& 就变为T&& &&, 并返回, 发生引用折叠T&&
std:move()和std::forward()都是转换变量用的不过
move()是将左值转换为右值引用做返回值
forward()则是将 变量原本表示的类型还给它因为, 模板函数传参可能会造成引用折叠, 并且右值引用对象做表达式时, 被看作左值
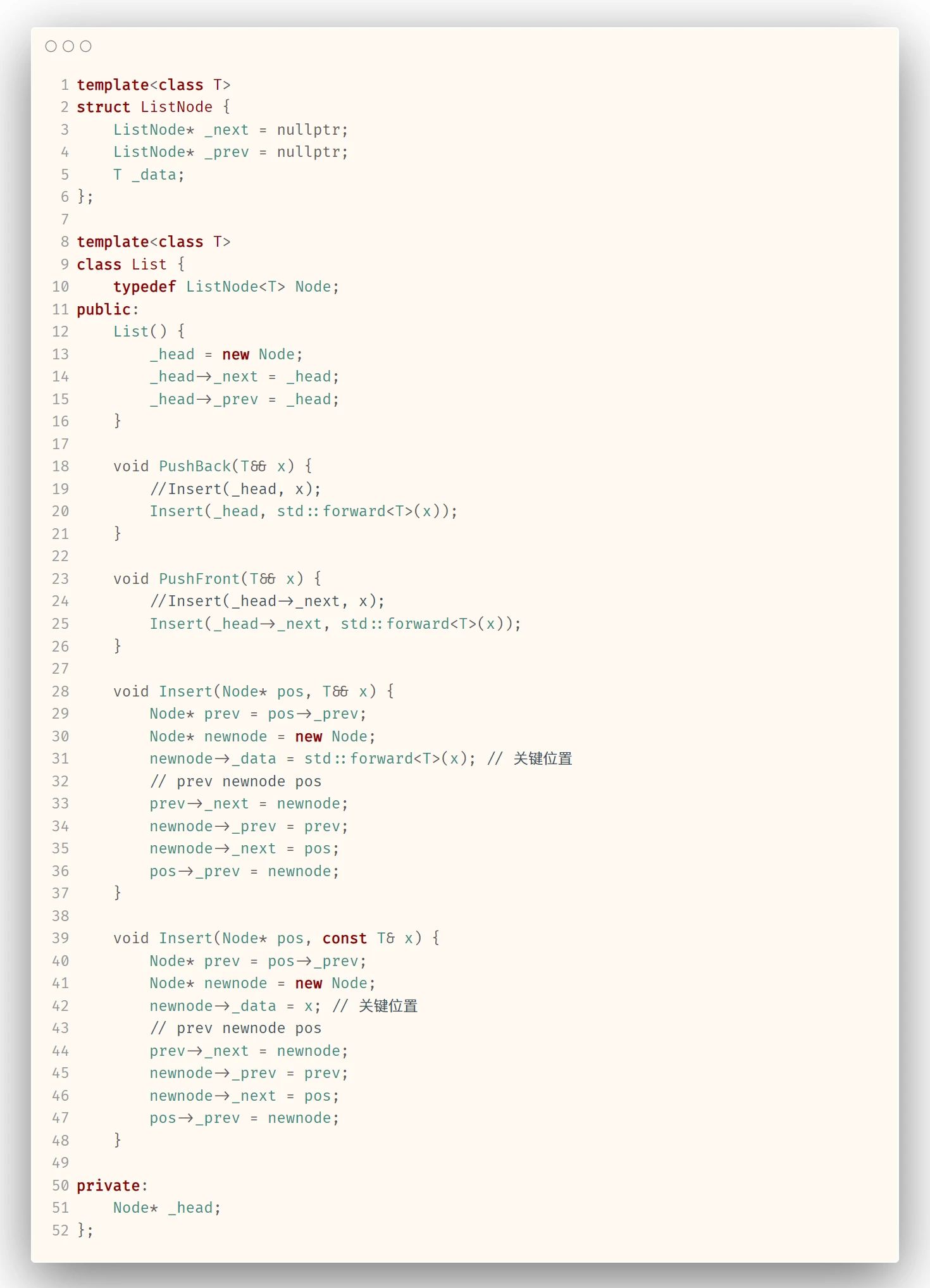
List 是一个模板类Insert()接口x就会变为左值形式, 所以要想实现node插入, 就要使用forward<>()将x恢复为右值引用, 才能调用Node结构体的移动赋值作者: 哈米d1ch 发表日期:2023 年 4 月 26 日