
[C++] 位图与布隆过滤器的相关介绍
位图
给40亿个不重复的无符号整数, 没排过序. 如何快速判断一个数是否在这40亿个数中?
首先分析问题:
- 40亿个无符号整数, 1个无符号整数4字节, 40亿个就是160亿字节
如果将这40亿个整数存放到内存中, 则需要 16GB 的内存
所以为了解决这类问题将所有数据存储到内存中, 不太现实
- 题目要求要快速判断, 所以遍历的方法首先就可以被OUT
那么可以想到的比较快速的查找方法就是: 二分查找
但是 二分查找的前提条件是: 1. 数据必须有序 2. 数据必须存储在连续的内存中
第一个条件可以用外排序解决, 但是第二个问题一般是没有办法解决的, 因为没有办法保证如此多的内存都是连续的
而位图就可以不浪费空间的解决这样的问题
什么是位图
位图的实现
位图的结构
vector<char>作为位图实现的底层, 那么每一个vector单元就是8个比特位:class bitset {
private:
vector<char> _bit;
}位图的构造函数
char来作为vector的单元类型, 那么如果需要8bit的话就至少需要开辟1个单元; 如果需要14bit的话, 就至少需要开辟2个单元; 如果需要16bit的话, 也至少需要开辟2个单元。class bitset {
pubilc:
bitset(size_t N) {
_bit.resize(N/8 + 1, 0); // 需要开辟N/8+1个空间, +1是为了保证比特位足够, 最多也就浪费8个比特位
}
private:
vector<char> _bit;
}数据在位图中的映射
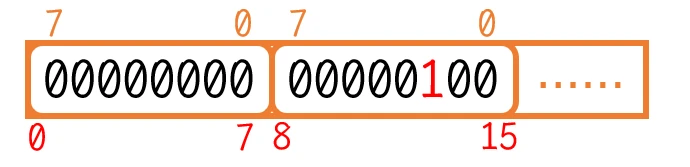
0或1的接口:
set:void set(size_t x) { size_t i = x / 8; // 算出x映射在第i个单元 size_t j = x % 8; // 算出x映射在第i个单元的第j个比特位上 _bit[i] |= (1 << j); // 将指定比特位设置为1 }
reset:void reset(size_t x) { size_t i = x / 8; size_t j = x % 8; _bit[i] &= (~(1 << j)); // 将指定比特位设置为0 }
判断数据是否在位图中
test:bool test(size_t x) {
size_t i = x / 8;
size_t j = x % 8;
return _bit[i] & (1 << j);
// 只要将整个单元数据 与上 只有第j位为1的数, 那么就可以根据结果判断出此位是否为1, 进而判断出数据是否在位图中
}位图解决问题
INT_MAX, 而不是40亿int的范围就是INT_MAX, 所以需要INT_MAX个比特位才能够表示所有整数的存在状态当然, 位图的首次映射也可能是一个漫长的遍历过程, 但是只要位图构建完成, 今后的数据判断的时间复杂度都将只是
O(1)
构建
INT_MAX位的位图, 至少需要使用256M-1=2^31-1 个 bit
总结
布隆过滤器
当某个文件中存储有100亿个
IP地址(可能相同)时, 怎么能将这些IP地址准确的映射到位图中呢?答案 显然是无法直接实现, 因为
IP地址很明显是属于字符串数据的, 字符串的数据想要映射到位图中, 就先要将字符串数据通过哈希算法计算为整型数据, 然后再将对应的整型数据映射到位图中
(BloomFilter)key数据就再位图上映射了多个位置, 只有这些位置上同时表示数据存在时, key数据才真正存在: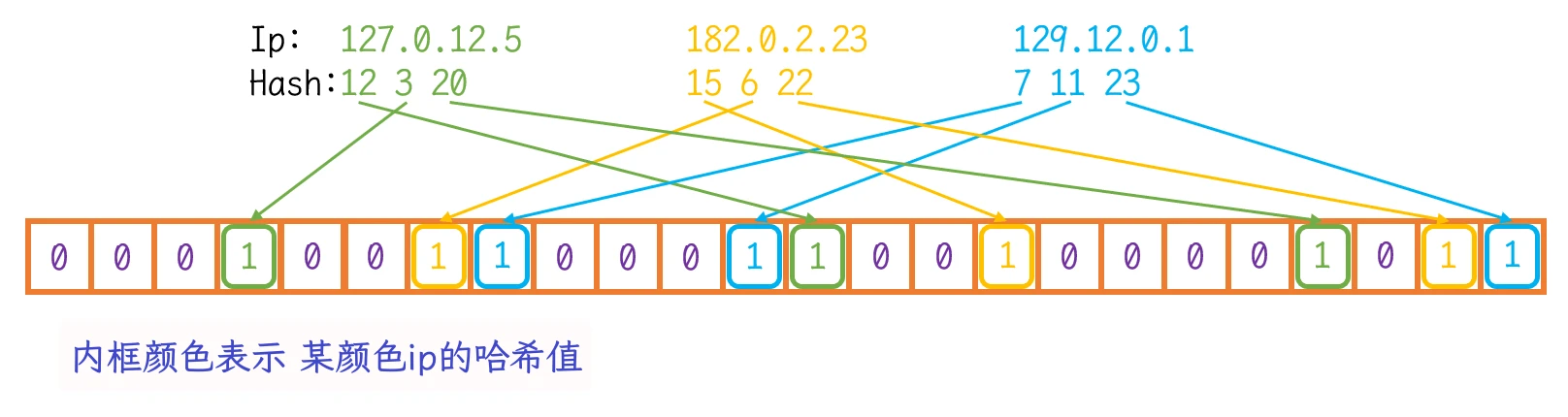
IP计算出的三个不同的哈希值在位图中映射同时存在时, 表示此IP存在IP的问题为例: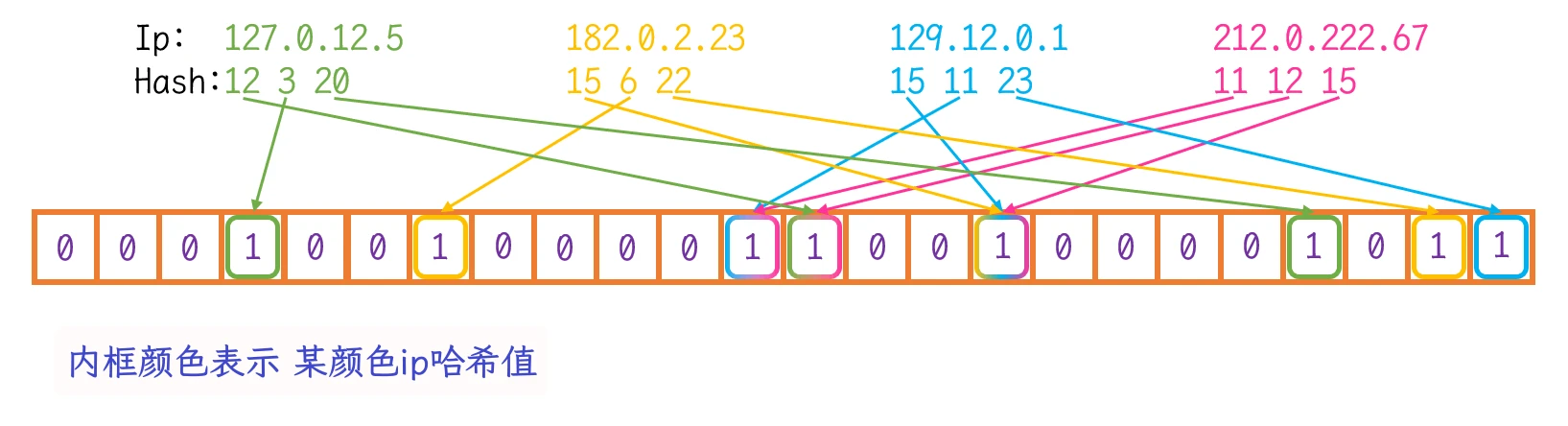
IP: 212.0.222.67计算出的三个哈希值分别是11、12、15, 而这三个哈希值也分别在其他的IP哈希值中IP的映射在位图中删除: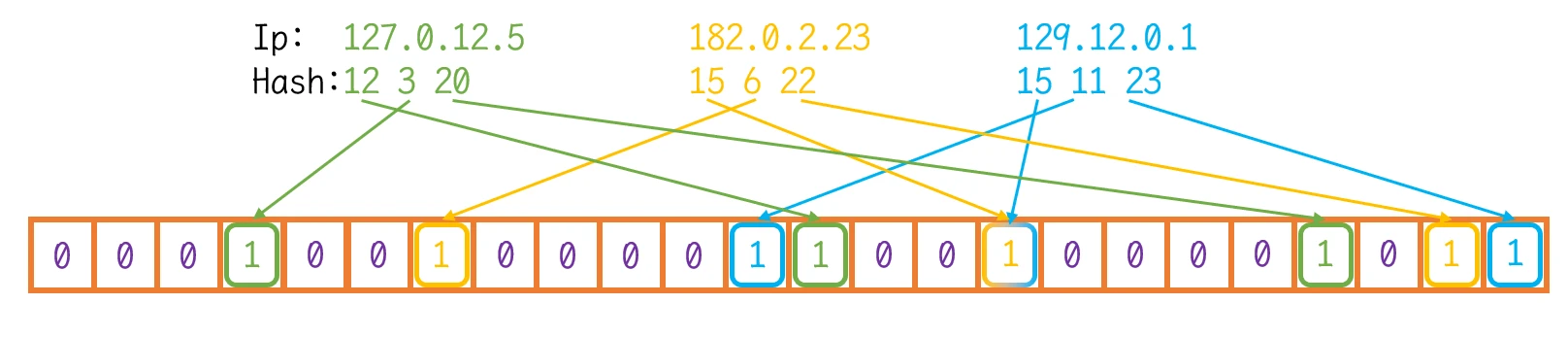
IP: 212.0.222.67计算出的三个哈希值11、12、15, 依旧映射在位图中IP: 212.0.222.67, 依旧可以在位图中查找到, 即使 此IP实际并没有在位图中映射: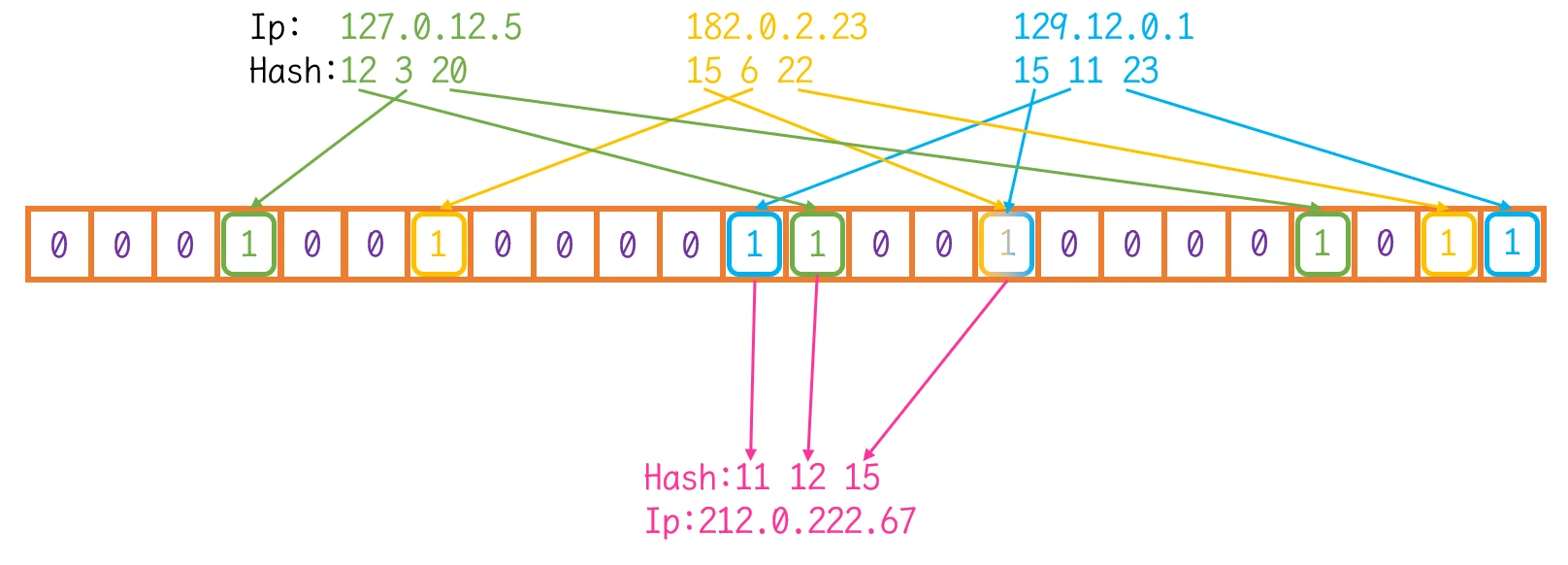
布隆过滤器的误报率, 与 哈希算法的个数、布隆过滤器比特位的个数 以及 需要映射的数据个数 都有关系
但具体的关系不再介绍, 这里推荐另一篇文章:
此文章中间部分通过数学与图例, 分析了布隆过滤器误报率相关因素的的影响关系
布隆过滤器的数据删除
- 删除一个数据, 需要删除多个哈希值映射
- 一个哈希值映射, 可能是多个数据的哈希值映射, 如果为了删除数据而直接删除此位置的哈希值映射可能会影响其他的数据
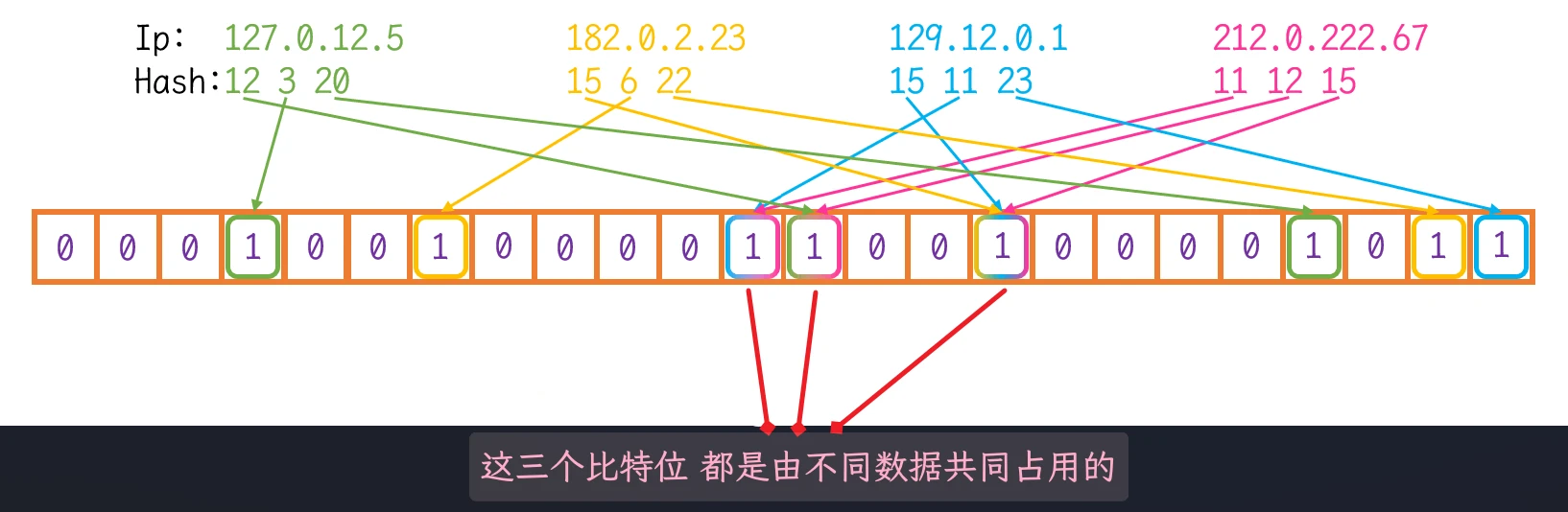
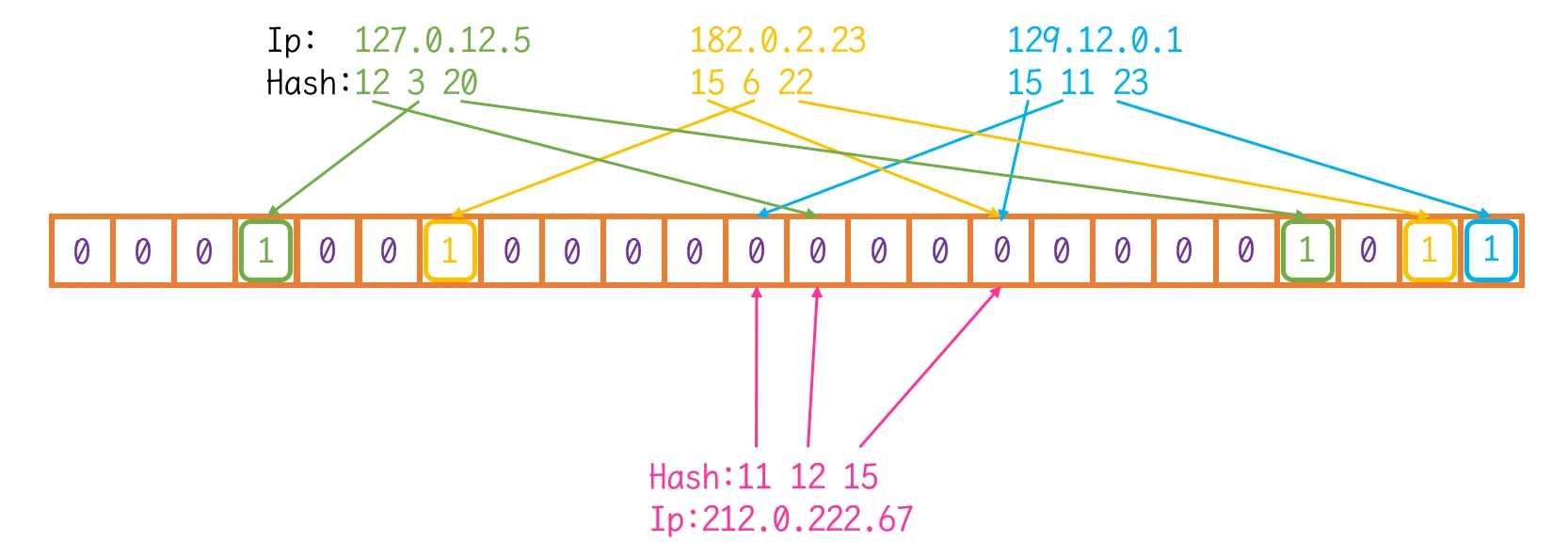
- 绿色IP 缺少了第12位的映射
- 蓝色IP 缺少了第11、15位的映射
- 黄色IP 缺少了第15位的映射
-
如何进行计数? 是使用其他容器然后针对各映射位进行计数? 还是在布隆过滤器本身进行计数?
布隆过滤器是为了处理海量数据节省内存而设计出来的, 如果再使用其他容器, 那么节省内存这个优势就没有了
那么就应该在布隆过滤器本身进行计数
Counting BloomFilter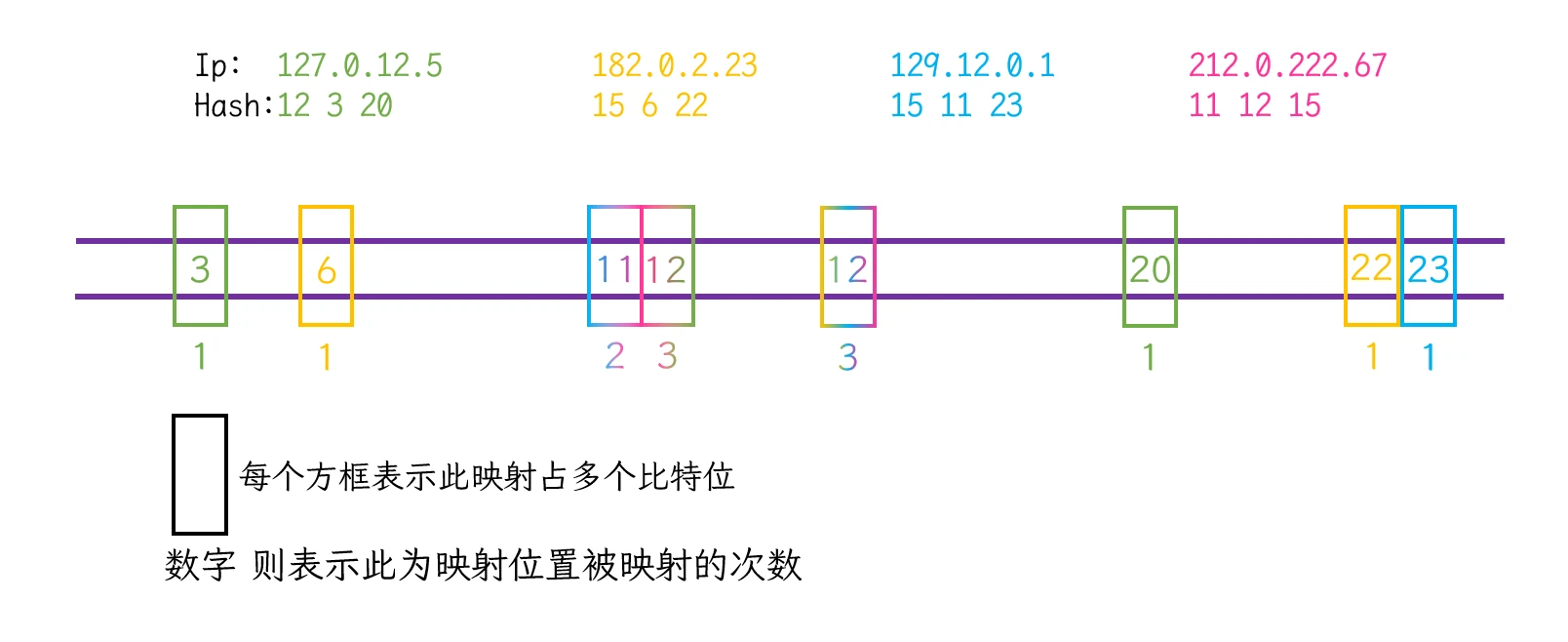
Counting BloomFilter的大致模型就应该是: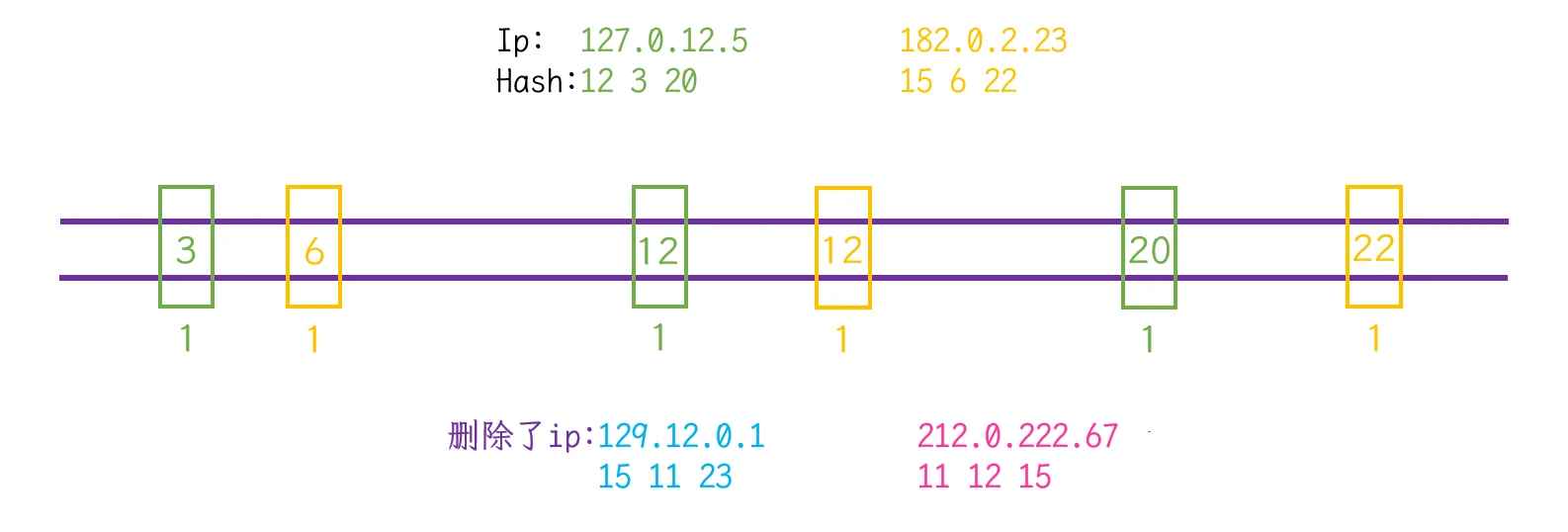
Counting BloomFilter的弊端
为什么是过滤器
即 布隆过滤器 使用多个哈希值进行映射减少了发生哈希冲突的概率, 但并不能完全避免哈希冲突
存在哈希冲突就有可能在查找时发生错误或误判, 即有一定的误报率
海量数据的处理
哈希切割
log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?我们都知道, 特定的哈希算法可以给 不同的数据 赋予各自可能唯一的哈希值
那么当海量的数据不能一下存储到内存中进行数据分析时, 可以使用特定的哈希算法计算出数据的哈希值, 并将哈希值相同的数据存放到另一个文件中, 思路像是将海量的数据按照哈希值进行分类, 将海量数据文件分为诺干小文件
此种方法就被称为
哈希切割
IP地址的哈希值, 将哈希值相同的IP存放到同一个文件中, 然后再使用红黑树等容器遍历文件统计IP的数量当然, 经过哈希切割的海量数据, 可能也会出现问题:
- 海量数据绝大部分或者全部都只是同一个数据, 经过哈希切割出来的文件也是非常大的文件, 依旧存在海量数据的情况
此种情况在统计的时候不会发生太大的问题, 因为在使用红黑树等容器遍历文件统计数量时, 容器中只会存储一个数据, 当遍历过程中再次遇到此数据时, 容器中并不会再次存储, 而只是进行统计 将计数进行++
所以, 不用担心此时会发生内存报错
- 发生哈希冲突, 即同一个文件中可能存在太多个不同的IP(太多表示依旧是海量数据)
当哈希切割之后, 同一个文件中依旧存在海量的不同IP, 又该怎么解决?
作者: 哈米d1ch 发表日期:2023 年 2 月 20 日