![[Linux] 详析 Linux下的 文件重定向 以及 文件缓冲区](https://dxyt-july-image.oss-cn-beijing.aliyuncs.com/202306251800381.webp)
Table of Contents
Linux中, 使用系统接口打开文件时, 系统会为打开的文件在此进程中分配fd, 而且是按照数组下标的顺序进行分配的
那么如果在打开新的文件之前, 有文件关闭了呢?再打开新的文件, 此文件的fd会分配什么呢?
文件描述符的分配规则 Link to 文件描述符的分配规则
一般情况下, 进程会默认先打开至少三个文件: 标准输入、标准输出、标准错误, 并分配fd为0、1、2
也就是说, 当进程使用open()打开磁盘文件时, 会从3开始分配fd.
那么如果在使用open()打开文件之前, 先关闭了0、1、2的描述的某个文件, 那么打开的文件会怎么分配fd呢?
123456789101112131415161718192021#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
umask(0);
close(0); // 什么都不干, 先关闭fd=0的文件
int fd = open("new_log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666); //以清空只写方式打开文件, 若文件不存在则创建文件
if(fd < 0) {
perror("open");
}
printf("打开文件的fd为: %d\n", fd);
close(fd);
return 0;
}
执行这段代码的结果是:

可以看到, 新打开的文件分配的fd变成了0. 如果我们关闭0、2文件, 再打开两个文件, 新打开文件的fd会怎么分配呢?

这意味着什么?这其实意味着, 打开文件分配fd的规则其实是, 从头遍历fd_array[]数组, 将没有使用的最小下标分配给新打开的文件
重定向 Link to 重定向
理解重定向 Link to 理解重定向
上面的测试中, 将fd = 0 和 2的文件关闭了, 并且打开的新文件的fd会被分配为0和2
那么也就是说, 如果我们把fd=1的文件关闭, 新打开文件的fd也会被分配为1
而我们知道, fd = 1是进程默认打开的标准输出, 对应着C语言中的stdout指针, stdout又被称为标准输出流, 使用fprint()可以向标准输出流写入内容, 从而可以将写入的内容打印在屏幕上.
#include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> int main() { umask(0); close(0); int fd = open("new_log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666); //以清空只写方式打开文件, 若文件不存在则创建文件 if(fd < 0) { perror("open"); } fprintf(stdout, "打开文件成功, fd: %d\n", fd); close(fd); return 0; }

那么, 如果我们关闭fd=1的文件, 再打开一个新的文件, 并使用C语言文件操作向stdout写入内容, 那么会发生什么呢?
123456789101112131415161718192021#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
umask(0);
close(1); // 什么都不干, 先关闭fd=1的文件
int fd = open("new_log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666); //以清空只写方式打开文件, 若文件不存在则创建文件
if(fd < 0) {
perror("open");
}
fprintf(stdout, "打开文件成功, fd: %d\n", fd);
fflush(stdout); // 刷新文件缓冲区操作
close(fd);
return 0;
}
关闭fd=1, fprintf()之后, 必须要手动刷新文件缓冲区, 不过暂时不做解释
本文章后面详析介绍文件缓冲区
代码的执行结果并没有在屏幕中输出任何信息. 那信息打印到哪里了呢?

此时当你查看刚刚打开文件的内容, 会发现, 原来应该打印到标准输出流的信息 打印到了刚刚打开的文件中
这是否就是重定向?
是的, 这就是重定向.
我们关闭了原来的fd=1文件(标准输出), 然后打开了一个新的文件分配了fd=1, 此时再向fd=1的文件中写入数据, 其实并没有向标准输出写入信息, 而是向指定文件写入了信息. 这其实就是输出重定向
整个过程可以用这个图表示:

我们把fd=1描述标准输出改为了描述一个指定文件, 这可以被称为重定向
那么重定向究竟是什么?
其实, Linux系统的上层只认0、1、2、3等这样的fd值, 我们在OS内部通过一定的方式 调整 数组特定下标的指向, 这样的操作就是重定向
如何重定向 Link to 如何重定向
上面再介绍重定向的概念时, 其实是通过关闭文件来实现重定向. 难道重定向都需要手动关闭文件, 然后再打开文件来实现吗?
其实不是的. 重定向归根结底是修改了系统内核中的数据来实现的, 既然是修改系统内核数据, 那么其实只有操作系统有权限. 那么对于上层来说, 想要实现重定向, 操作系统就一定会提供接口:
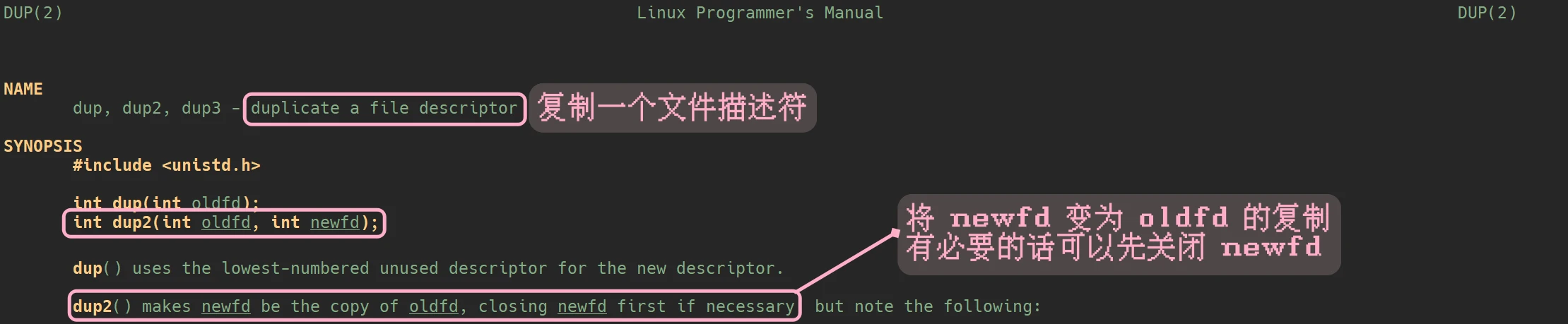
操作系统提供了几个重定向的接口, 不过在本篇文章中只介绍dup2()
1int dup2(int oldfd, int newfd);
man手册中, 关于此系统接口的描述是: 复制一个文件描述符, 将 newfd 变为 oldfd 的复制
这是什么意思?
dup2()使用时需要传入两个参数, oldfd 和 newfd. 并且 会将newfd变为oldfd的复制, 也就是说dup2()操作的是两个已经打开的文件
dup2()是系统为重定向提供的接口, 也就是说 dup2()会将一个fd描述的文件重定向为另一个文件
那么 newfd 和 oldfd, 哪个是重定向之后的文件, 哪个又是重定向之前的文件呢?
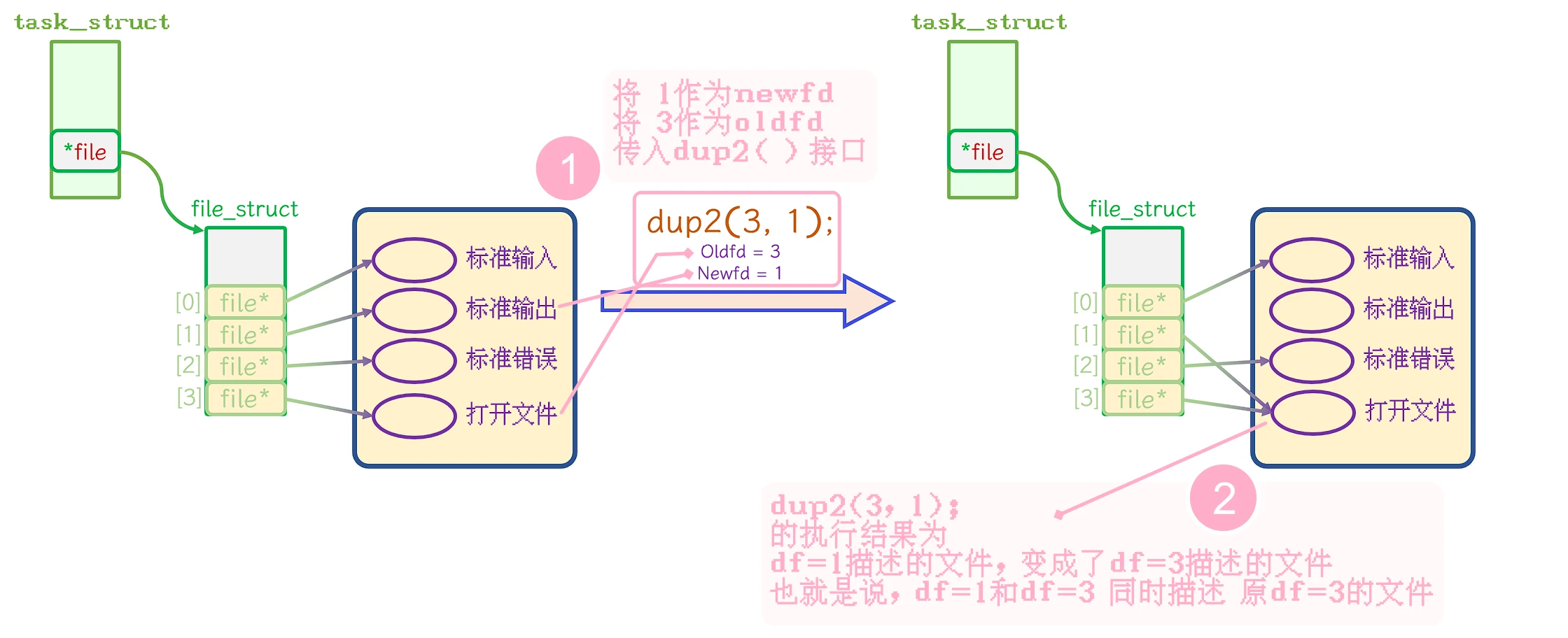
读dup2()的描述其实可以了解到, dup2()其实会将 newfd 变为 oldfd, 也就是说执行过dup2()之后, 其实进程中已经不在维护原来的newfd, newfd和oldfd 只剩了oldfd. 从这个结果可以看出来, oldfd其实是重定向之后的文件, 而newfd是被重定向掉的文件
即, dup2(oldfd, newfd); 是将 newfd位置的内容变成了oldfd位置的内容.
再用 将stdout重定向到了指定文件 来举例就是:
dup2()实现输出、追加重定向 Link to dup2()实现输出、追加重定向
上面介绍了dup2()的作用和用法, 那么就可以使用此系统接口实现重定向
先来实现一下输出和追加重定向:
1234567891011121314151617181920212223#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main() {
umask(0);
int fd = open("new_log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666); //以清空只写方式打开文件, 若文件不存在则创建文件
if(fd < 0) {
perror("open");
}
dup2(fd, 1); // 将标准输出重定向到只写打开文件, 实现输出重定向
const char *buffer = "Hello world, hello July\n";
write(stdout->_fileno, buffer, strlen(buffer));
close(fd);
return 0;
}

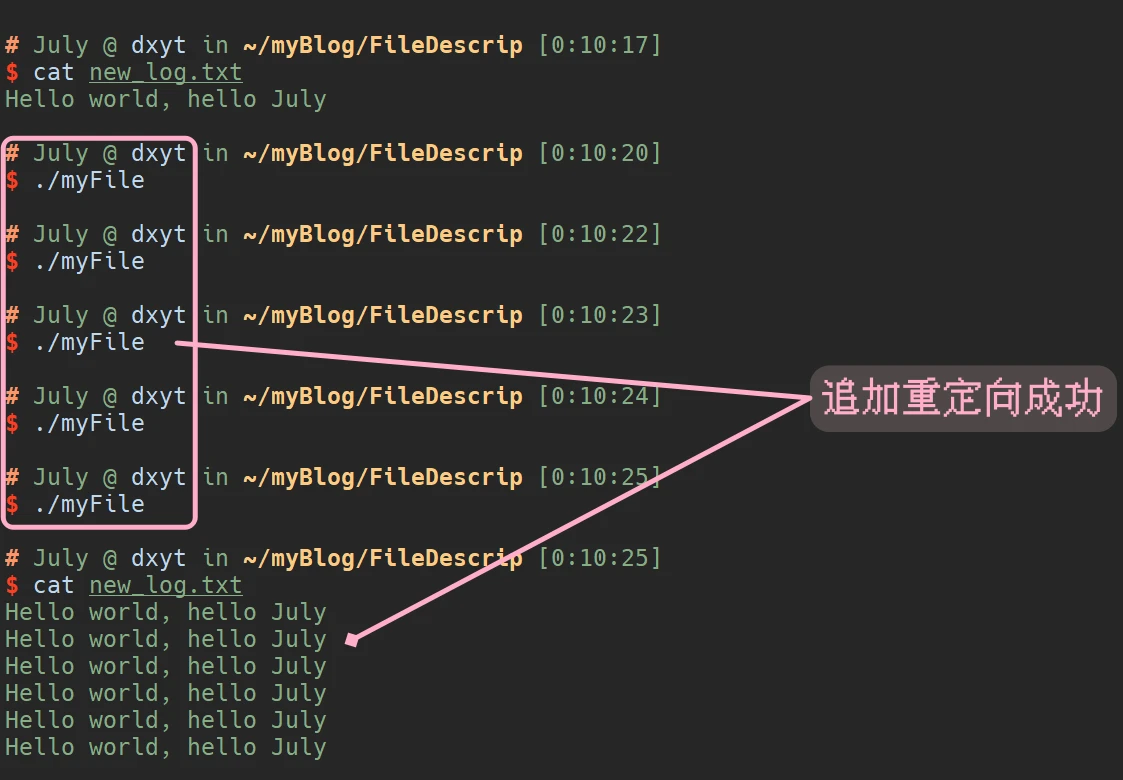
当, 以 追加并写入的方式打卡文件时, 就可以实现追加重定向:
1234567891011121314151617181920212223#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main() {
umask(0);
int fd = open("new_log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666); //以清空只写方式打开文件, 若文件不存在则创建文件
if(fd < 0) {
perror("open");
}
dup2(fd, 1); // 将标准输出重定向到只写打开文件, 实现输出重定向
const char *buffer = "Hello world, hello July\n";
write(stdout->_fileno, buffer, strlen(buffer));
close(fd);
return 0;
}
dup2()实现输入重定向 Link to dup2()实现输入重定向
将标准输出重定向到指定文件可以实现输出重定向
那么将标准输入重定向到指定文件, 是否就可以实现输入重定向呢?
123456789101112131415161718192021222324#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main() {
int fd = open("new_log.txt", O_RDONLY); //以只读方式打开文件, 只读打开一般都是已存在的文件
if(fd < 0) {
perror("open");
}
dup2(fd, 0); // 将标准输入重定向到只读方式打开的文件, 实现输入重定向
char buffer[128];
// 从stdin中获取数据到buffer中
while(fgets(buffer, sizeof(buffer), stdin) != NULL) {
printf("%s", buffer);
}
close(fd);
return 0;
}

文件缓冲区 Link to 文件缓冲区
在学习C语言时, 可能就有人听说过文件缓冲区. 但是对其并没有一个正确的认识
下面就来介绍一下, Linux系统中的文件缓冲区
什么是文件缓冲区 Link to 什么是文件缓冲区
简单的来讲, 文件缓冲区其实就是一块内存空间
这块空间是用来, 存储 向系统内核中写入的数据 的.
就向我们在使用printf(), 并且不刷新文件缓冲区时, 并不会直接将数据打印到屏幕上:
123456789101112131415#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main() {
printf("Hello world");
write(stdout->_fileno, "I am a process", strlen("I am a process"));
sleep(3);
return 0;
}
这段代码的执行结果是:
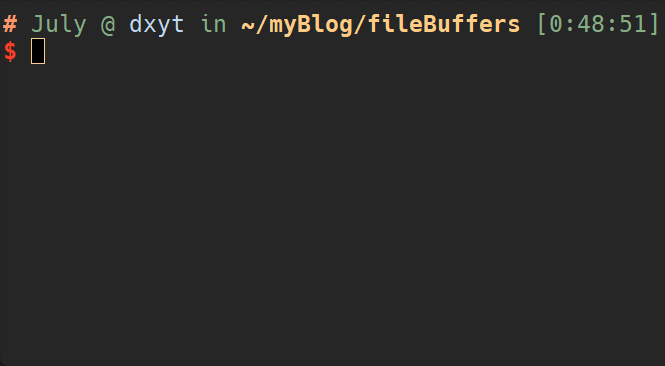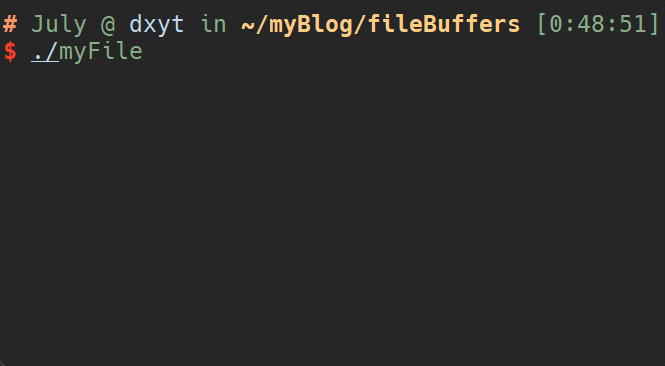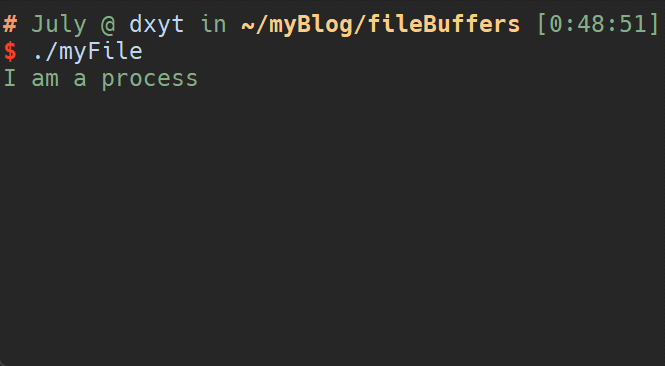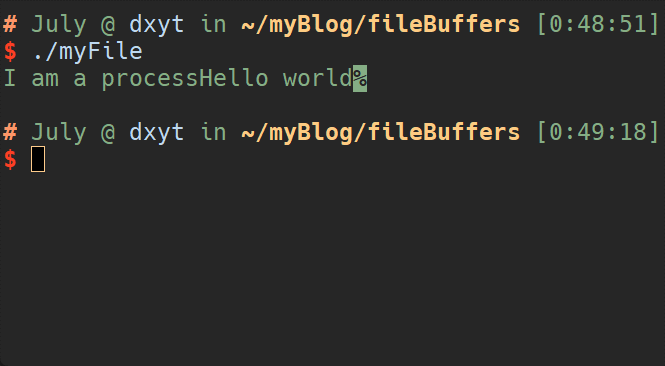
可以看到, 明明在printf()之后的 write()语句先输出了.
这就可以说明文件缓冲区的存在, 并且只有在刷新文件缓冲区时, 文件缓冲区内的数据才会写入系统内核中
为什么要存在文件缓冲区 Link to 为什么要存在文件缓冲区
首先, 文件缓冲区是存放 进程向操作系统内核写入的数据 的
就以向屏幕上输出信息为例:
我们知道, 进程在等待硬件资源时是会进入
阻塞状态的处于阻塞状态的进程, 无法执行其他代码, 只能等到阻塞结束
而进程向屏幕输出信息时, 其实也是需要屏幕资源的
如果此时屏幕资源已经被占用满了, 并且没有文件缓冲区的存在, 输出语句执行就会进入阻塞状态等待屏幕资源
而如果有文件缓冲区的存在, 即使屏幕资源已经被占满了, 输出语句执行之后, 会将需要输出的信息存入文件缓冲区中, 然后进程继续执行其他代码. 等到合适的时候, 再刷新文件缓冲区 将需要打印的信息打印到屏幕上
这样看, 其实
文件缓冲区的存在, 在一定程度上节省了进程使用缓冲区(此缓冲区非文件缓冲区)的时间如果没有文件缓冲区的存在, 我们打印信息就会立马在屏幕上打印出来.
这样看起来似乎不错, 但其实会加重操作系统的负担.
如果没有限制的、死循环地向屏幕上打印信息, 那么数据就会在操作系统与硬件之间疯狂地I/O操作.
这样显然会加重操作系统的负担.
而有了文件缓冲区地存在, 在不满足刷新文件缓冲区地条件时, 我们需要打印的信息就会先存放在文件缓冲区中, 暂时不与硬件发生I/O操作. 直到达成刷新文件缓冲区的条件时, 再将文件缓冲区内的所有数据刷新到屏幕上.
这样,
文件缓冲区的存在, 其实可以集中处理数据刷新, 有效的减少操作系统与硬件之间的I/O次数, 进而提高整机的效率
文件缓冲区在什么地方 Link to 文件缓冲区在什么地方
知道了什么是文件缓冲区, 有了解了文件缓冲区存在的某些意义. 那文件缓冲区到底在什么地方呢?
还记得上面那段代码的执行结果吗?
123456789101112131415#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main() {
printf("Hello world");
write(stdout->_fileno, "I am a process", strlen("I am a process"));
sleep(3);
return 0;
}
这段代码的执行结果是, 先输出了"I am a process", 然后在3s之后输出了"Hello world"
这样的结果可以确定一个结论: 系统接口wirte(), 是不存在文件缓冲区的, 所以用write()向标准输出写数据, 会直接在屏幕中打印出来
而 printf(), 如果不刷新缓冲区的话, 就不会将需要打印的信息打印出来. 且 C语言的printf() 一定是封装了write()接口的.
也就是说, Linux下 printf()最终可以在屏幕上打印数据, 一定是在内部调用了write()接口. 但是 write()打印数据是会直接打印出来的.
那么, 提问: 文件缓冲区在什么地方?或者这里应该问: 文件缓冲区在什么地方使用了?
答: 文件缓冲区一定是在printf()内部使用了.
文件缓冲区在printf()的内部被使用了, write()没有使用文件缓冲区. 难道文件缓冲区是由语言提供的吗?
是的, 文件缓冲区就是由语言本身提供的, 与操作系统无关.
C语言中的FILE是一个结构体, 里面封装了许多与文件相关的属性, 其中就包括fd(_fileno) 和 文件缓冲区
在Linux平台中, /usr/include/stdio.h 文件内 有一句: typedef struct _IO_FILE FILE;:

这就是C语言中我们熟知的 FILE结构体. 那么 struct _IO_FILE{} 具体是什么呢?
在相同的目录下: /usr/include/libio.h 文件内, 存储着 struct _IO_FILE{} 相关内容:
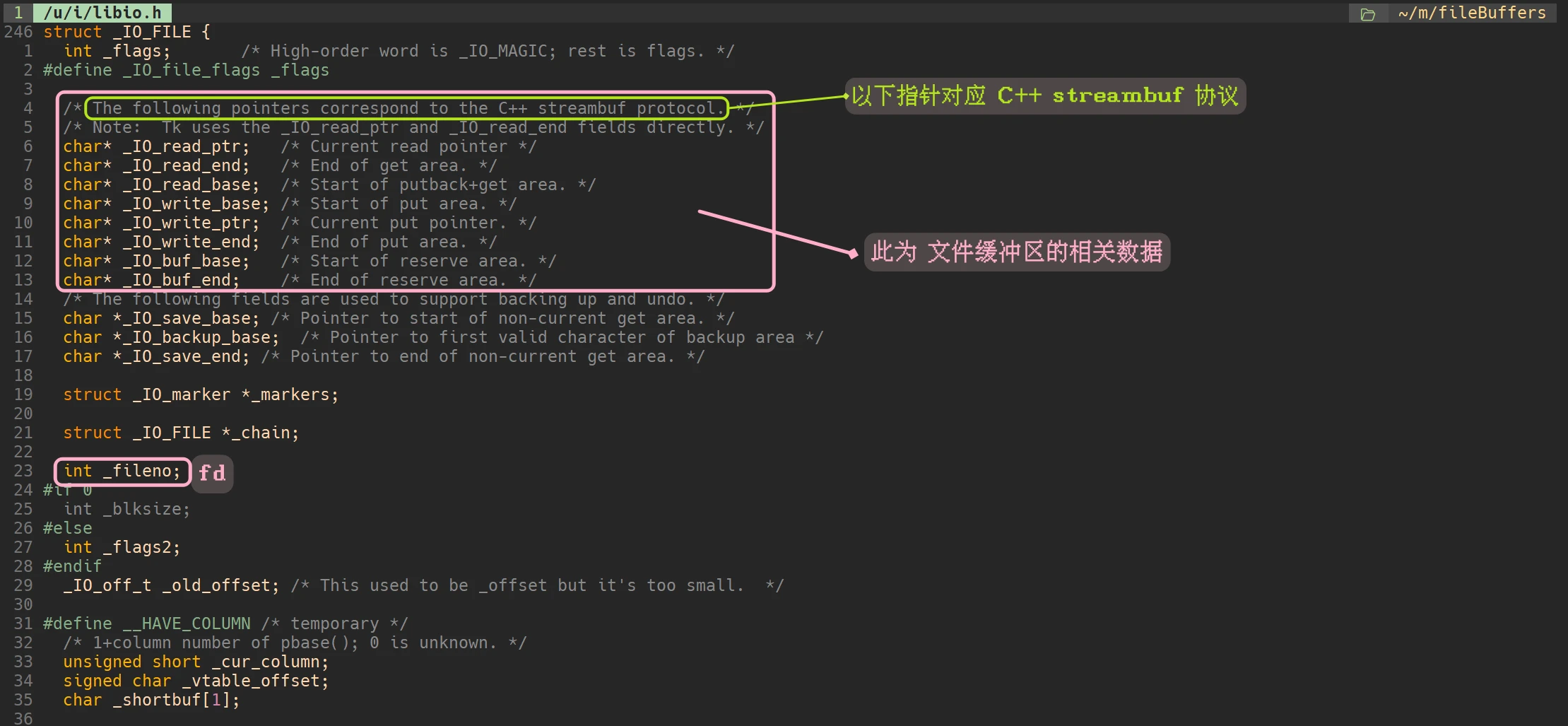
C语言中, 文件缓冲区的相关描述, 其实一直存储在 FILE结构体 中. 与操作系统无关
文件缓冲区在FILE结构体中描述着.
而使用C语言的文件接口, 每打开一个文件就会返回一个FILE*
那么是否, **
C语言每个打开的文件都有自己独立的文件缓冲区**呢?是的.
那么也就是说, 当我们使用printf、fprintf、fputs等C语言提供的 均封装了write()的 向其他文件中写入数据的接口时, 其实都会使用到C语言提供的文件缓冲区.
这块缓冲区被描述在C语言的FILE结构体中. 只有在缓冲区被刷新时, 才会真正调用writr()接口向文件中写入数据:
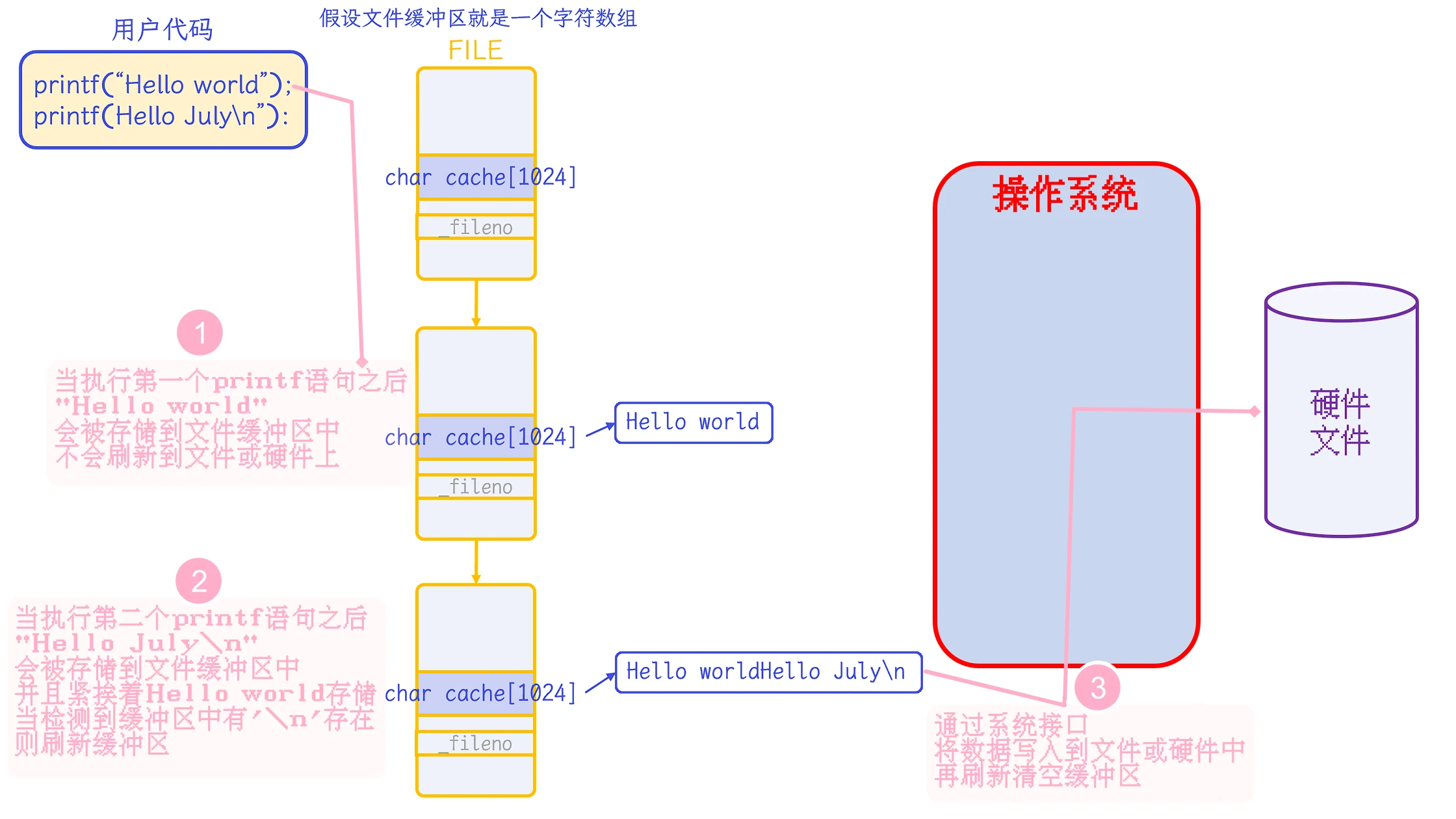
C语言中存在着文件缓冲区, 并且在合适的时候需要清空缓冲区.
那么究竟什么时候清空缓冲区呢??或者说 缓冲区的刷新策略是什么?
还有 如果在刷新缓冲区之前, 我们将fd关闭会发生什么?
下面就来测试一下:
12345678910111213141516171819#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main() {
printf("Hello July");
fprintf(stdout, "Hello July");
fputs("Hello July", stdout);
// 如果没有关闭stdout, 这三个语句会在进程结束时正常在屏幕上输出
// 进程退出会自动刷新缓冲区
// 我们在这里将 stdout 关闭
close(stdout->_fileno);
return 0;
}
执行上面的代码, 可以发现:
屏幕上什么都没有打印.
而, 当我们不关闭stdout时:

执行代码就会在屏幕上打印三个"Hello July"
即, 在刷新缓冲区之前, 关闭指定的fd, 缓冲区内的数据就不能被写入到指定的fd中了
缓冲区的刷新策略 Link to 缓冲区的刷新策略
文件缓冲区是用来减少I/O次数的, 而不是禁止I/O的.
所以文件缓冲区需要在合适的时候将数据写入到系统内核, 然后刷新缓冲区
那么文件缓冲区的刷新策略是什么呢?
一般情况下, 文件缓冲区存在三种刷新策略:
- 无缓冲, 即立即刷新. 每次存储到缓冲区的内容都会被立即写入系统内核数据, 并刷新缓冲区
- 行刷新, 即遇到
'\n'时刷新. 我们使用的printf() 这种向显示器文件中写入数据的 一般就采用的行刷新策略, 当输出的内容结尾处有'\n'时, 会将'\n'及之前的数据打印出来 - 全刷新, 即
缓冲区满再刷新. 全刷新策略一般在向块设备对应的文件(例如磁盘文件)中写入数据时会采用
然而, 还有特殊的情况:
- 当进程退出的时候, 文件缓冲区会自动刷新
- 用户可以强制刷新文件缓冲区,
fflush()函数就是这个作用
* 奇怪的问题 Link to * 奇怪的问题
我们了解了文件缓冲区, 那么以两种不同的方式执行这段代码, 试着分析为什么会出现不同的情况:
12345678910111213141516171819202122232425include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main() {
const char* str1 = "Hello printf\n";
const char* str2 = "Hello fprintf\n";
const char* str3 = "Hello fputs\n";
const char* str4 = "Hello write\n";
// C库函数
printf("%s", str1);
fprintf(stdout, str2);
fputs(str3, stdout);
// 系统接口
write(stdout->_fileno, str4, strlen(str4));
fork();
return 0;
}
正常编译运行:
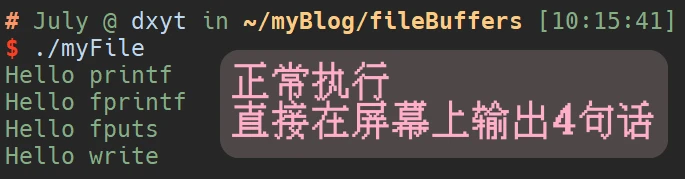
输出重定向到文件中
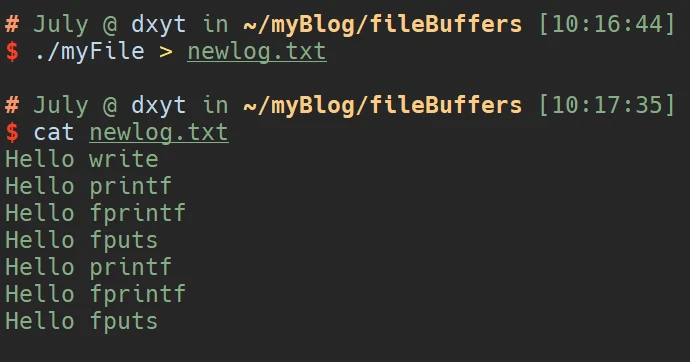
你会发现, 直接运行屏幕上输出了4句话, 但是如果是输出重定向到文件中, 文件中会被写入7句话
这是什么原因呢?
首先, 针对第一种情况:
虽然使用了fork()创建子进程, 但是 是在上面四条语句执行完之后 才创建的. 而且正常执行的话, 四个语句都是向屏幕中打印数据, 所以采用的是行刷新, 所以每个语句执行完之后都会直接在屏幕中打印数据并刷新缓冲区. 子进程也不会执行fork()之上的代码
所以屏幕上输出了四句话
那么针对第二种情况呢?
我们首先要明确, 文件缓冲区是由FILE结构体维护的, 是属于父进程内部的数据
第二种情况是在运行时, 输出重定向到了一个文件中. 那么文件缓冲区的刷新策略就改变了, 上面介绍过向文件中写入数据, 文件缓冲区的刷新策略是全刷新. 所以在执行前三个语句时, 会将三句话都存储到文件缓冲区内 且不刷新. 而执行系统接口 wirte()是没有缓冲区 的, 所以会率先写入到文件中.
之后, 进程会创建子进程. 我们知道, 子进程和父进程在不修改数据时是 共享一份代码和数据的. 而无论父子进程谁要修改数据, 就会发生写时拷贝. 子进程被创建时, 很明显父进程的文件缓冲区还没有被刷新. 那么也就是说 子进程创建出来时, 是与父进程共享同一份文件缓冲区的. 那么接下来, 无论是子进程先终止, 还是父进程先终止, 都需要清除共享的文件缓冲区. 而fork()父子进程修改数据的机制是, 只要修改就会发生写时拷贝, 所以在 进程要清除文件缓冲区时, 另一个进程会先拷贝一份. 拷贝完成之后, 先终止的进程就会刷新文件缓冲区, 将缓冲区内的数据写入到文件中, 然后另一个进程终止, 将拷贝的文件缓冲区也刷新掉, 将相同的数据写入到文件中.
至此, 就造成了此例中, 文件内被写入七句话
写一份自己的C文件操作库, 并实现文件缓冲区 Link to 写一份自己的C文件操作库, 并实现文件缓冲区
要深刻理解文件缓冲区, 可以模仿C文件操作写一份简单的自己的文件操作库.
但是不能调用C库中的文件操作函数
myFILE结构 Link to myFILE结构
首先, C库维护文件使用的是FILE结构体, 我们也可以设置一个myFILE结构体, 不过不需要太多的成员:
12345678#define SIZE 1024 // 缓冲区大小
typedef struct _myFILE {
int _fileno; // 首先需要存储文件的fd
char _buffer[SIZE]; // 设置一个1024字节的缓冲区
int _end; // 用来记录缓冲区目前长度, 即结尾
int _flags; // 用来选择缓冲区刷新策略
}myFILE;
my_fopen()函数 Link to my_fopen()函数
我们的需要仿照fopen()来实现, 通过不同的传参来以不同的方式打开文件:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647// 宏定义缓冲策略, 以便执行
#define NONE_FLUSH 0x0
#define LINE_FLUSH 0x1
#define FULL_FLUSH 0x2
myFILE* my_open(const char* filename, const char* method) {
// 两个参数, 一个文件名, 一个打开模式
assert(filename);
assert(method);
int flag = O_RDONLY; //打开文件方式 默认只读
if(strcmp(method, "r") == 0) {} // 只读传参, 不对flag做修改
else if(strcmp(method, "r+") == 0) {
flag = O_RDWR; // 读写, 文件不存在打开失败
}
else if(strcmp(method, "w") == 0) {
flag = O_WRONLY | O_CREAT | O_TRUNC; // 清空只写, 文件不存在创建文件
}
else if(strcmp(method, "w+") == 0) {
flag = O_RDWR | O_CREAT | O_TRUNC;
}
else if(strcmp(method, "a") == 0) {
flag = O_WRONLY | O_CREAT | O_APPEND; // 追加只写, 文件不存在创建文件
}
else if(strcmp(method, "a+") == 0) {
flag = O_RDWR | O_CREAT | O_APPEND;
}
int fileno = open(filename, flag, 0666); // 封装系统接口打开文件
if(fileno < 0) {
return NULL; // 打开文件失败
}
// 打开文件成功, 则为myFILE开辟空间
myFILE* fp = (myFILE*)malloc(sizeof(myFILE)); // 有开辟失败的可能
if(fp == NULL) {
return fp;
}
memset(fp, 0, sizeof(myFILE)); // 将开辟的空间全部置0
fp->_fileno = fileno; // 更新 myFILE里的_fileno
fp->_flags |= LINE_FLUSH; // 默认行刷新
fp->_end = 0; // 默认缓冲区为空
return fp;
}
此函数, 封装了系统接口open(), 打开文件, 并返回初始化过的myFILE指针
可以在main()函数中测试一下:
12345678int main() {
myFILE* pf = my_open("newlog.txt", "w+");
printf("打卡文件的fd: %d\n", pf->_fileno);
printf("打卡文件缓冲区占用: %d\n", pf->_end);
return 0;
}

my_fclose()函数 Link to my_fclose()函数
123456789101112131415161718void my_fflush(myFILE* fp) {
assert(fp);
if(fp->_end > 0) { // _end记录的是 缓冲区内数据的长度
write(fp->_fileno, fp->_buffer, fp->_end); // 向fd中写入缓冲区数据
// 这里不在判断是否写入成功
fp->_end = 0;
syncfs(fp->_fileno); // 我们只向内核中写入了数据, 数据可能存储到了操作系统中 文件系统的缓冲区中, 需要刷新一下文件系统的缓冲区
// 与文件缓冲区不同
}
}
void my_fclose(myFILE* fp) { // 暂时忽略返回值
// 再关闭文件之前, 需要先刷新缓冲区, 所以可以先写一个刷新缓冲区的函数
my_fflush(fp);
close(fp->_fileno); // 封装系统接口close()关闭文件
free(fp); // 记得free掉 malloc出来的空间
}
my_fclose() 的实现, 重点在关闭文件前缓冲区的刷新, 和 free()掉malloc的空间
my_fwrite()函数 Link to my_fwrite()函数
my_fwrite()的实现, 重点在刷新缓冲区的策略上.
无缓冲和全刷新的实现, 还算简单. 一个不需要判断, 另一个只需要判断缓冲区是否存满
重点是行刷新如何实现?
行刷新的策略是: 只要缓冲区内存在'\n' 就将'\n'及以前的所有数据刷新出去.
不过 我们可以实现的简单一些, 只判断缓冲区末尾是'\n'就刷新
我们模拟实现C文件操作是为了加深对文件缓冲区的理解, 而不是为了完善函数和算法模拟
12345678910111213141516171819202122232425void my_fwrite(myFILE* fp, const char* start, int len) {
assert(fp);
assert(start);
assert(len > 0);
strncpy(fp->_buffer + fp->_end, start, len); // 将start 追加到_buffer原内容之后
fp->_end += len; // 更新一下 _end;
// 刷新缓冲区
if(fp->_flags & NONE_FLUSH) {
// 无缓冲
my_fflush(fp);
}
else if(fp->_flags & LINE_FLUSH) {
// 行刷新
if(fp->_end > 0 && fp->_buffer[fp->_end-1] == '\n') { // 需要访问_end-1位置, 所以要先判断_end > 0
my_fflush(fp);
}
}
else if(fp->_flags & FULL_FLUSH) {
if(fp->_end == SIZE) { // SIZE是缓冲区的大小
my_fflush(fp);
}
}
}
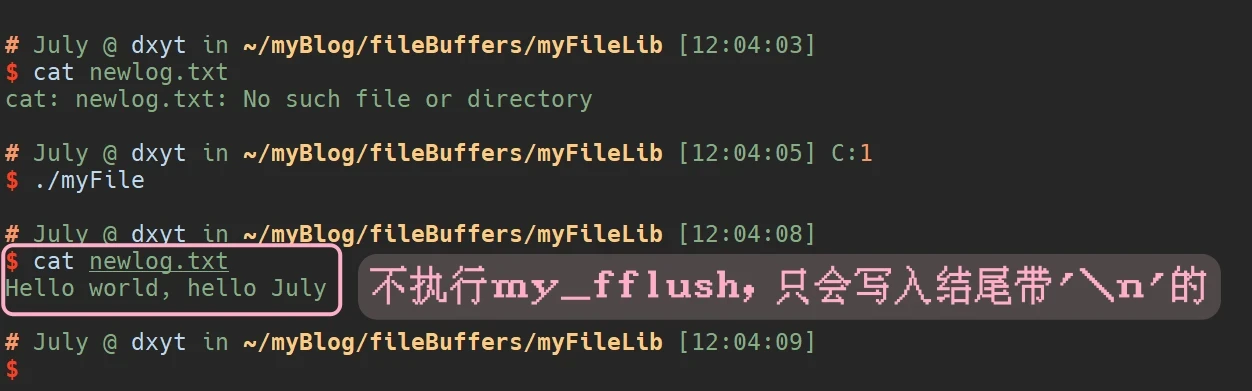
可以通过下面的代码验证一下:
12345678910111213int main() {
myFILE* pf = my_open("newlog.txt", "a+");
const char* buf1 = "Hello world, hello July";
const char* buf2 = "Hello world, hello July\n";
my_fwrite(pf, buf2, strlen(buf2));
my_fwrite(pf, buf1, strlen(buf1));
// my_fflush(pf); // 可以看一下词语执行与否的差别
return 0;
}

再谈重定向 Link to 再谈重定向
本篇文章的第二个部分, 已经介绍过Linux中的重定向. 但是似乎和我们一直在使用的重定向不太一样.
实现命令行重定向 Link to 实现命令行重定向
一般来说, 重定向都是在命令行中确定的.
而上面介绍的重定向只是在进程内部调用dup2()进行重定向. 那么如何实现在命令行中使用 > >> < 实现重定向呢?
实现 命令行中的重定向, 可以在之前实现简易shell中添加功能.
重定向的实现的具体内容, 可以去阅读博主这篇文章:
简易shell博客地址
命令行重定向的用法 Link to 命令行重定向的用法
标准输出与标准错误 Link to 标准输出与标准错误
在正式介绍命令行重定向的用法之前, 先来介绍一下 标准输出fd=1和标准错误fd=2这两个文件, 在C语言中对应着 stdout 和 stderr
Linux内存文件中, 这两个被打开的文件一般都是显示器. 也就是说, 不论是向fd=1还是fd=2写入数据, 一般情况下都是向显示器写入数据
那么执行这段代码, 其实都会向屏幕上打印内容:
123456789101112131415161718192021222324252627#include <cstdio>
#include <iostream>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <cstring>
#include <cerrno>
int main() {
// stdout
printf("hello printf fd=1\n");
fprintf(stdout, "hello fprintf fd=1\n");
fputs("hello printf fd=1\n", stdout);
// stderr
fprintf(stderr, "hello fprintf fd=2\n");
fputs("hello fputs fd=2\n", stderr);
perror("hello perror fd=2");
// cout
std::cout << "hello cout fd=1" << std::endl;
// cerr
std::cerr << "hello cerr fd=2" << std::endl;
return 0;
}
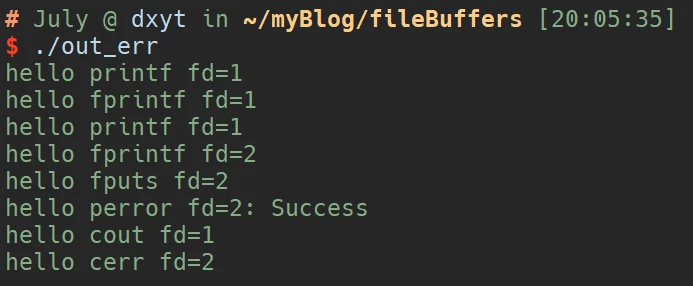
这段代码分别向标准输出和标准错误打印了4句话, 那么当我们执行代码并输出重定向到文件中时:
./out_err > out_err.txt

这意味着什么?
这其实意味着, 虽然 标准输出和标准错误 都表示显示器, 但是并不是一同控制的
默认的输出重定向是修改的标准输出, 那么如果想修改标准错误, 应该怎么控制呢?
重定向的完整用法 Link to 重定向的完整用法
如果想要重定向把标准错误修改为指定文件, 该怎么控制呢?
在介绍之前, 先看一下这个命令: ./out_err 1> out_err.txt

那么如果是这个呢?./out_err 2> out_err.txt
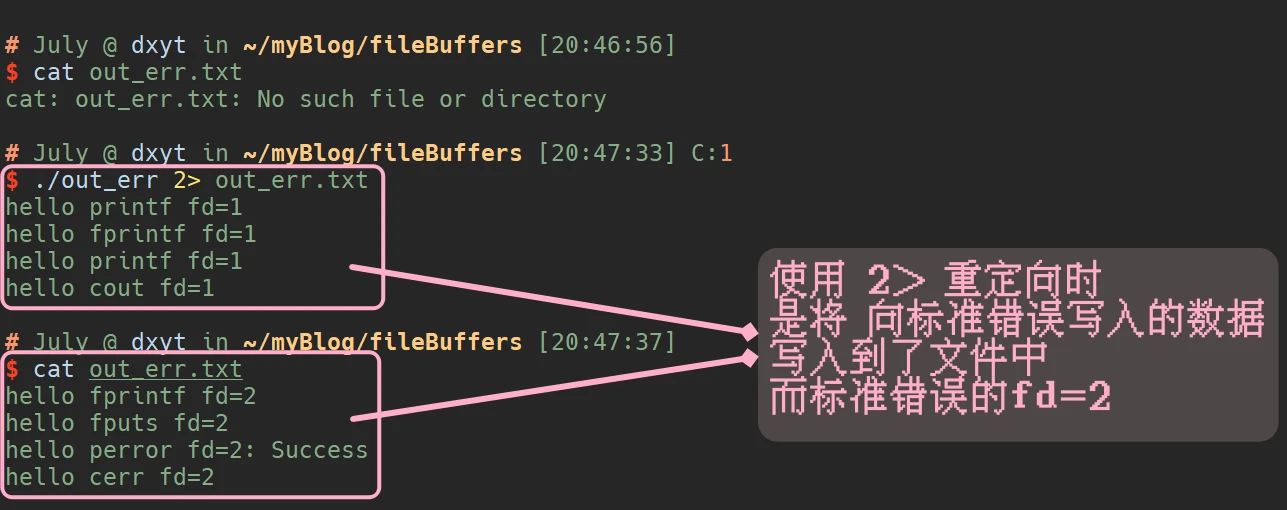
使用 1> 重定向 是输出重定向, 而使用 2> 重定向 则是错误重定向
那么命令行中, 重定向的完整正确用法是否是这样的 —––> 命令 fd> 文件
是的, 命令行中重定向符号的完整使用, 其实是 fd>:
0> 是输入重定向, 1> 是输出重定向, 2> 是错误重定向, >> 是追加重定向
重定向其他用法 Link to 重定向其他用法
我们已经知道了 1> 是输出重定向, 2> 是错误重定向.
那么**可不可以同时输出重定向和错误重定向**?
是可以的, 就像这样:
./out_err 1> out.txt 2> err.txt
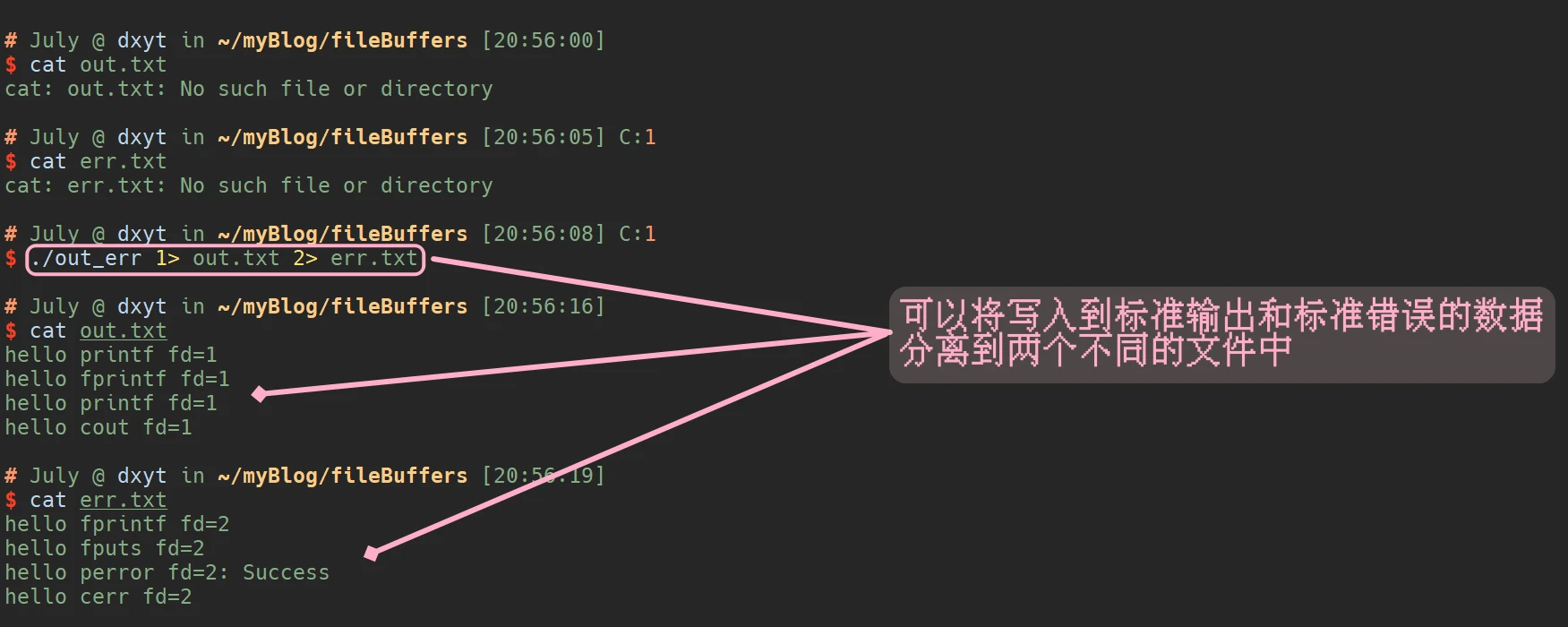
这样的重定向用法, 可以分离程序的运行日志, 可以将运行错误日志分离出来以便分析
这样是将输出重定向和错误重定向分别重定向到不同的文件中
可不可以 将输出、错误重定向同时重定向到同一个文件中?
其实也是可以的:
./out_err 1> all.txt 2>&1
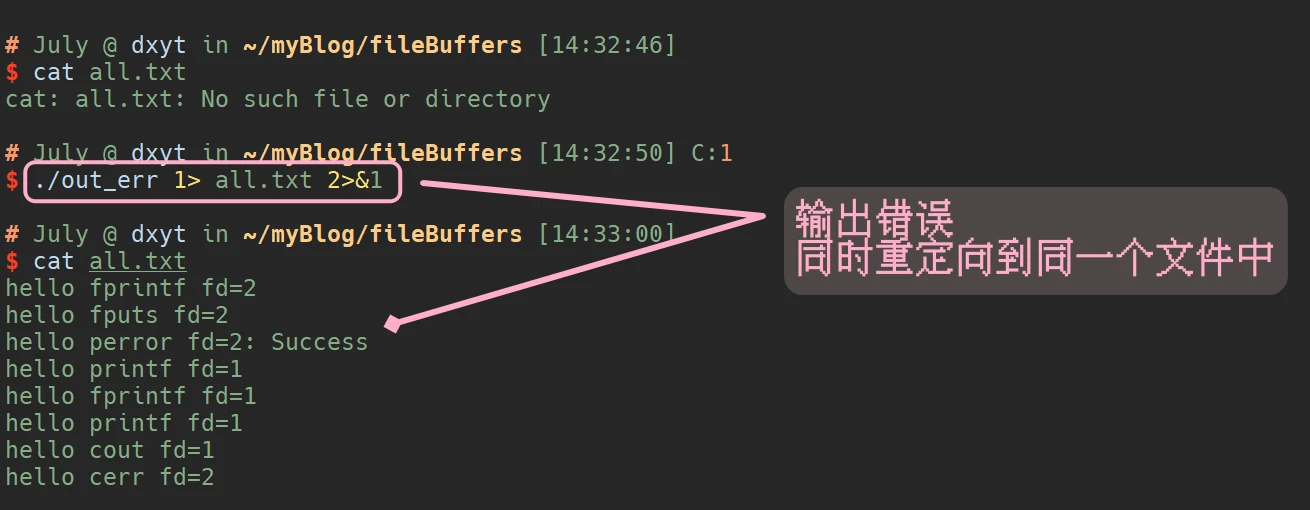
2>&1的操作, 可以看作 是
将标准错误输出重定向
[Linux] 详析 Linux下的 文件重定向 以及 文件缓冲区
© 哈米d1ch | CC BY-SA 4.0